Graphlit Blog
Insights on AI-powered knowledge management, multimodal content processing, RAG, and building intelligent applications.

The Agent Is the User
Three products now share the 'company brain' label: orchestration platforms, AI-native apps, and real context graphs. The agent is the user, and the data model decides the moat.

AI Agent Memory Frameworks in 2026: Memory vs. Context
A 2026 survey of AI agent memory frameworks and the shift from vector-store chat history to structured, temporal, self-editable context systems. Compare Mem0, Supermemory, Membase, Memory Store, Zep, Graphiti, LangMem, Cognee, CrewAI, LlamaIndex, and Graphlit.
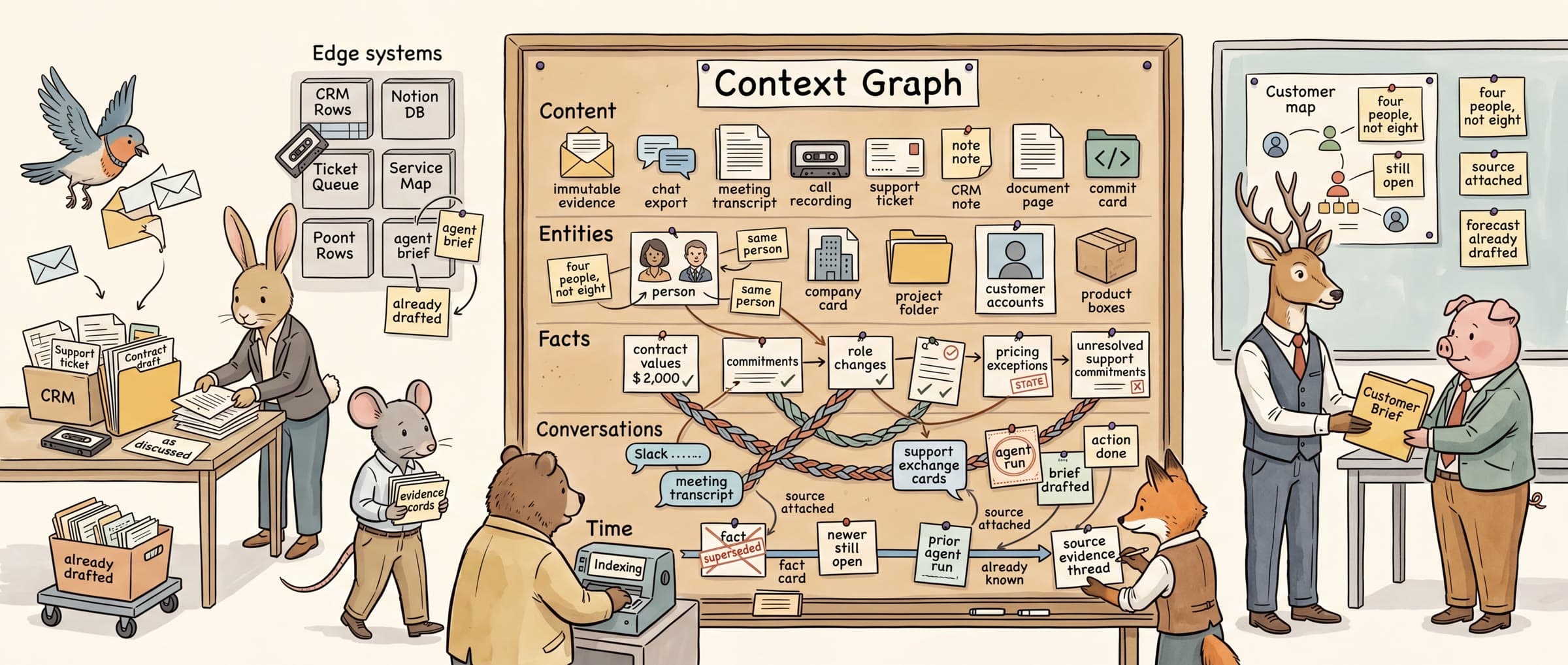
Context Graphs, Honestly
Foundation Capital is right that context graphs matter. Forrester is right they were not invented yesterday. Matt Brown explains why the data model is still the moat.

Introducing the New Zine: AI Chat That Actually Knows Your Life
Every AI chat app lets you pick a model. None of them know your stuff. Zine is different: every conversation grounded in your notes, email, and files. This is AI chat that actually knows you.

Introducing Dossium: The Customer Context Platform
Everything your team knows about a customer, unified and accessible to humans and AI agents alike. We're building the customer context platform.

Context Graphs: What the Ontology Debate Gets Wrong
Prescribed vs learned ontologies? It's a false dichotomy. The foundations already exist—Schema.org, CDM, WAND. The real unsolved problems are temporal validity, decision traces, and fact resolution.

Building the Event Clock
The 'two clocks' insight is exactly right: we've built infrastructure for state, almost nothing for reasoning. Here's what we've learned building the event clock—and why facts as first-class data are the key.

The Context Layer AI Agents Actually Need
Foundation Capital's context graph thesis is compelling. But building one requires solving the operational context problem first. Here's what it takes.

File Search vs. RAG: Understanding the Difference and Why It Matters
File search finds documents. RAG generates answers. Understanding when to use each—and when you need both—is crucial for building effective AI applications.

Compare PDF to Markdown Extraction Using the JFK Files
With the release of the JFK Files, it provided a robust set of real-world examples of scanned and handwritten PDFs.

Graphlit MCP Server: Integrate with MCP clients such as Goose, Cline and Claude Desktop
Launch of our open-source MCP (Model Context Protocol) Server for Graphlit, providing powerful content ingestion and retrieval capabilities for Claude Desktop, Goose, Cline, Cursor, and Windsurf.

Comparison of Web to Markdown Conversion APIs
For many RAG applications and AI agents, ingesting web content and converting to Markdown is the starting point for the unstructured data pipeline.

Building a Streaming AI Chat with the Graphlit TypeScript SDK
Learn how to build a real-time streaming chat interface using Graphlit's streamAgent. Complete tutorial with Next.js, TypeScript, and practical code examples.

Graphlit 2024 Year in Review
Reflecting on a Year of Innovation As we look back on 2024, it's clear that Graphlit has experienced a year of remarkable growth and innovation.

Build CrewAI Agents with Graphlit Agent Tools
Graphlit's new Agent Tools for Python library enables easy interaction with agent frameworks such as CrewAI, allowing developers to easily integrate...

Feature Comparison of RAG-as-a-Service Providers
With Carbon being acquired by Perplexity last week, we've been talking to many ex-Carbon customers about transitioning to Graphlit.

Comparison of Knowledge Graph Generation Across LLMs
Compare knowledge graph generation approaches using Named Entity Recognition models like Azure AI Text Analytics versus leading LLMs including OpenAI GPT-4o, Anthropic Claude 3.5 Sonnet, and Google Gemini 1.5.

Comparison of API Services for PDF Extraction to Markdown
There's a wide variety of services available now for extracting complex PDFs, especially those with tables, into Markdown format.
-scrape-website-thumb.jpeg&w=3840&q=75&dpl=dpl_5gDytPFe13iyLfs6XfqCUpD7aUNY)
30 Days of Graphlit (Day 2): Scrape Website
Welcome to the '30 Days of Graphlit', where all month during September 2024 we will show a new Python notebook example of how to use a feature (or...
-extract-markdown-from-pdf-thumb.jpeg&w=3840&q=75&dpl=dpl_5gDytPFe13iyLfs6XfqCUpD7aUNY)
30 Days of Graphlit (Day 1): Extract Markdown from PDF
Welcome to the '30 Days of Graphlit', where all month during September 2024 we will show a new Python notebook example of how to use a feature (or...

Testing Claude 3.5 Sonnet for document text extraction
There are many approaches for performing text extraction from documents, like PDFs and Word documents.Classically, Optical Character Recognition (OCR) has be...

Build LLM-driven applications with Next.js, Vercel and Graphlit
We have built three new sample applications, which show the capabilities of Graphlit integrated with Next.js, and deployable on Vercel.

Evaluating Modern Web Scraping Techniques
Introduction Web scraping has become an indispensable tool for extracting data from the vast expanses of data available on the internet.

PDF Ingestion Using Graphlit
IntroductionNavigating through the complex structure of PDF documents to extract usable data poses a significant challenge due to their non-uniform format an...

A Deep Dive into LlamaIndex and Graphlit for Streamlined Development
Introduction Have you found yourself juggling multiple tools alongside LlamaIndex in your project and realized that managing them has become more...

GraphRAG: Using Knowledge in Unstructured Data to Build Apps with LLMs
As we have seen with Retrieval Augmented Generation (RAG), integrating LLMs with unstructured data can be valuable for a wide range of use cases.

Langchain vs Graphlit: Building a Q&A System
Imagine you're a developer tasked with building an AI-powered application that can answer questions based on information from a specific website.

Analyzing GitHub Issues with Graphlit
Building on the groundwork in our previous article, we're about to get hands-on with Graphlit, turning it from a concept into a working model that...

Introduction to Knowledge Graphs
Knowledge Graphs stand as a pivotal technology shaping the future of how machines understand and interact with the vast universe of data.

Diving Into Open Source with Graphlit: A Beginner's Guide to Contributing and Collaborating
A beginner's guide to contributing to open-source software. Learn how to collaborate on projects like Firefox, Python, and Graphlit, and join the vibrant world of open-source repositories and innovation.

Building a Conversational Slack Bot with Graphlit
Guest Author: Kaushil Kundalia (kaushil.kundalia@gmail.com) Prerequisites: Slack workspace with admin privileges Ngrok installed Install all the...

ETL for LLMs: Extracting Knowledge from Content
Learn how to leverage LLMs and RAG in structured ETL pipelines to extract knowledge from unstructured data across support tickets, emails, Slack messages, documentation, and website content.

The Value of Unstructured Data for LLMs
In today's data-centric world, unstructured data forms the vast majority of information generated and consumed across various platforms and industries. Unlik...

GPT-to-Audio: Publish AI-Generated Podcasts with Graphlit, GPT-4 and ElevenLabs
Text-to-speech models such as those from ElevenLabs have become incredibly human-sounding, and have the ability to clone your own voice.

Publish LLM-Generated Audio Alerts to Slack with Graphlit, GPT-4 and ElevenLabs
As we showed in the previous GPT-to-Audio tutorial, integrating LLMs such as OpenAI GPT-4 with text-to-speech models from ElevenLabs can generate compelling ...

Multimodal Content Publishing: Apartment Inspection Reports with Graphlit and GPT-4 Vision
Multimodal Content PublishingWith the latest multimodal models, such as OpenAI GPT-4 Vision, the Graphlit Platform can be used to repurpose not just textual ...

Structured Data From Unstructured Data: Address Extraction with Graphlit, GPT-4 Turbo
Extract Postal Addresses Many AI-enabled applications need to extract structured data from unstructured data, i.e. web pages, PDFs, or audio transcripts.

Comparing RAG Copilots from OpenAI, Anthropic, Perplexity and more
With the wide variety of Large Language Models (LLMs) available today, and with the recent announcement of OpenAI Assistants, I thought it would be interesti...

LLMs for Podcasters: Automating Content Workflows with Graphlit, MapScaping, Deepgram and OpenAI GPT-4 Turbo
Introduction Before starting Graphlit, I was an avid podcast listener but always felt like there was untapped value in the knowledge presented in each...

Auto-Suggest LLM Prompts, with Graphlit and Azure OpenAI
Auto-Suggest LLM Prompts When creating a chatbot or AI copilot, which supports Q&A across ingested content, a common user problem can be knowing where...

Model-Agnostic Text Summarization With Anthropic, Azure OpenAI and OpenAI LLMs
Model-Agnostic Text Summarization For long-format content, like an ArXiV research paper, Large Language Models (LLMs) can expedite your learning by...

Multimodal RAG: Using Graphlit, OpenAI GPT-4 Vision for Insurance Adjustment
Multimodal LLMsWith OpenAI's release of their GPT-4 Vision model, it has opened up the ability to analyze visual content (images and videos) and gather insig...

Exploring Market Intelligence Data with Graphlit, Reddit and OpenAI LLMs
Recap Our goal is to leverage the unstructured data from Reddit, along with APIs and LLMs from Azure and OpenAI, to build a conversational knowledge...

Market Intelligence with Graphlit, Reddit and Azure AI
Market Intelligence Market intelligence encompasses a wide range of insights, such as competitor activities, consumer trends, and emerging...