
Introduction
Navigating through the complex structure of PDF documents to extract usable data poses a significant challenge due to their non-uniform format and embedded elements like images, plots and tables. In this article, we will talk about the challenges of extraction PDF data and how you can use Graphlit to ingest pdf data and use an LLM to unlock interactive question-answering capabilities.
Challenges in PDF Data Extraction
PDFs are one of the most common document formats used across various industries due to their ability to maintain a consistent layout across different devices. However, the very features that make PDFs so versatile also create significant challenges for data extraction:
- Non-Standard Layouts: PDFs often contain complex layouts with multicolumn texts, sidebars, and mixed content types like text, images, and tables interspersed. This variability can confuse tools that extract plain text, leading to incomplete or inaccurate data retrieval.
- Embedded Content: Text in PDFs may be embedded as images, especially in scanned documents, making it inaccessible for text extraction tools without optical character recognition (OCR) capabilities.
- Inconsistent Text Flow: The logical reading order in a PDF might not match the visual presentation. For example, columns on a page might be read left to right when they are intended to be read from top to bottom, which can disrupt data extraction accuracy.
- Font and Encoding Issues: PDFs allow for embedding custom fonts, which might not be recognized by standard PDF readers or extraction tools, resulting in garbled or missing text during extraction.
- Metadata and Security Features: PDFs can contain metadata and may be secured with encryption or usage restrictions, complicating data extraction without appropriate permissions or tools.
How PDF Data Extraction Works
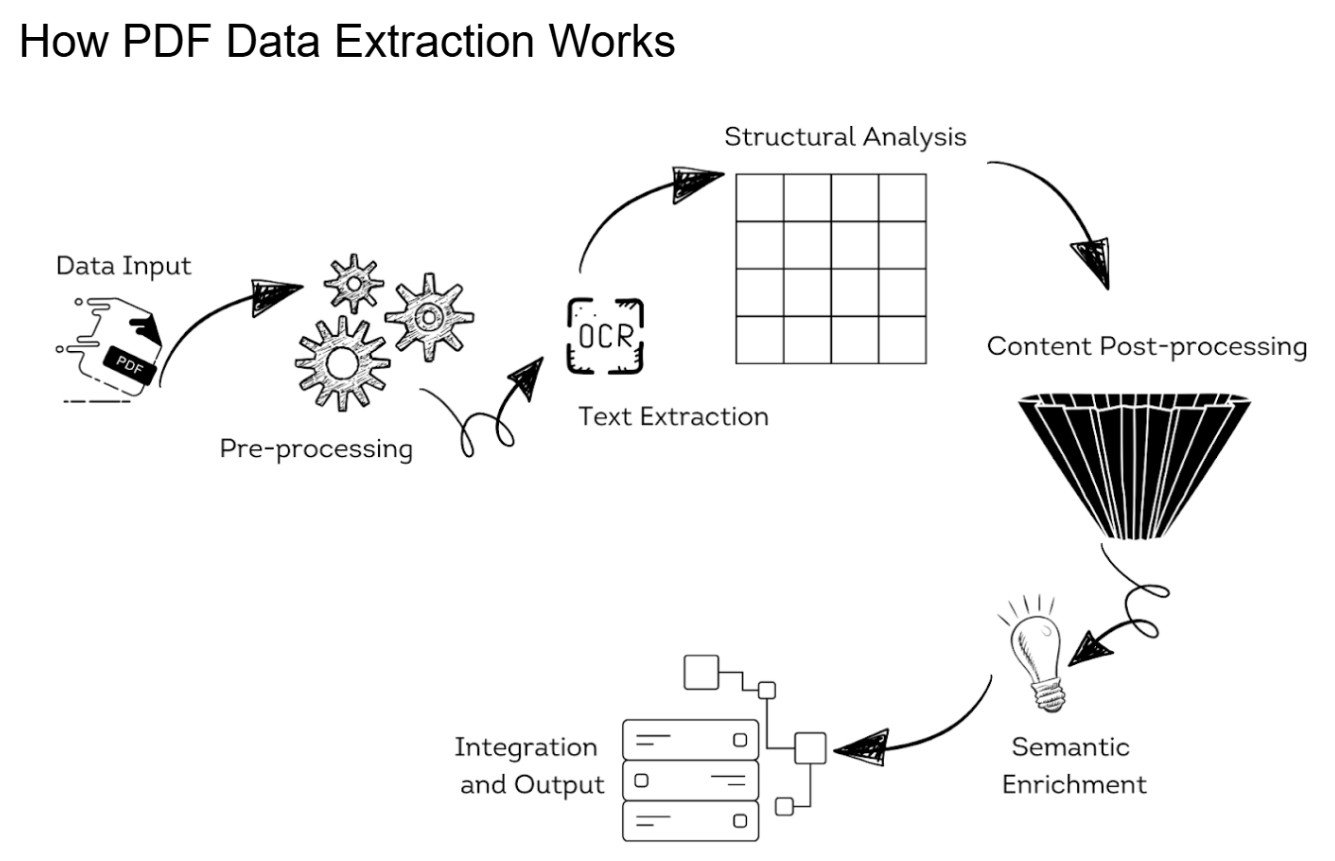
To overcome these challenges, effective PDF data extraction employs a variety of techniques and technologies, typically involving several stages:
-
Pre-processing:
- Normalization: Converts all data into a uniform format.
- Image Pre-processing: To improve OCR results for scanned documents, image quality enhancement techniques such as de-skewing, noise reduction, and contrast adjustment are applied.
-
Text Extraction:
- OCR: Used for scanned PDFs to convert image-based content into selectable and searchable text.
- Text Recognition: Tools parse the text layer of digital PDFs to extract readable content. This involves understanding the PDF's internal structure to differentiate between actual text and graphical elements.
-
Structural Analysis:
- Layout Parsing: Identifies the structural elements of a PDF, such as columns, headers, footers, and paragraphs. This is crucial for maintaining the logical flow of content.
- Table and Graph Detection: Specialized algorithms detect and reconstruct tables and charts to preserve data integrity and relationships.
-
Content Post-processing:
- Data Cleansing: Removes any artifacts or errors introduced during OCR or text extraction.
- Validation: Ensures the extracted data matches expected formats or schemas, using techniques like pattern recognition or checksums.
-
Semantic Enrichment:
- Entity Recognition: Identifies and classifies entities such as dates, names, and locations within the text.
- Contextual Analysis: Tools apply natural language processing to infer context and meaning from the text, enhancing the richness of the extracted data.
-
Integration and Output:
- Data Structuring: The extracted information is structured into a format suitable for further analysis or storage, such as JSON, XML, or directly into a vector databases.
- Output Delivery: Data is made accessible to users or downstream applications, often through APIs or direct export options.
PDF extraction involves multiple steps, such as document conversion, layout analysis, text extraction, and data parsing. Tackling these steps by yourself can be overwhelming and divert your focus from building your core application and serving your users. Graphlit simplifies the entire process of PDF ingestion and data extraction by providing an easy API.
To get started with Graphlit, all you need is the URL of the PDF you want to ingest and a Graphlit account. With just a few lines of code, you can integrate Graphlit into your application and start processing PDFs effortlessly.
Using Graphlit to Ingest PDF Data
There are a few ways we can ingest PDF data into Graphlit. The easiest way to ingest PDFs is to use the ingestURI mutation. You can also try this out in the API Explorer.
You will need to specify the URI for the PDF. In my example, I am using the Arxiv link for the “Attention Is All You Need” paper.
Mutation:
mutation IngestUri($uri: URL!) {
ingestUri(uri: $uri) {
name
id
}
}
Variables:
{
"uri": "https://arxiv.org/pdf/1706.03762"
}
Response:
{
"data": {
"ingestUri": {
"name": "1706.03762",
"id": "c701c43b-68b5-4be1-8d15-347ccd3594b0"
}
}
}
And that’s it, you can now start a conversation in Graphlit or use the QueryContents mutation to start a chat and Graphlit will inject relevant context from this PDF into your chat context!
You can also use Graphlit’s Python API to ingest the PDF. To do that, you will first need to install the graphlit-client package:
!pip install graphlit-client -q
Next you need to initialize your Graphlit client with your organization ID, environment ID, and JWT secret. You will find these values in your project settings in the Graphlit portal.
from graphlit import Graphlit
graphlit = Graphlit(
organization_id="<your-org-id-here>",
environment_id="<your-env-id-here>",
jwt_secret="<your-jwt-secret-here>"
)
Then, you can use the ingest_uri method to ingest your pdf.
uri="https://arxiv.org/pdf/1706.03762"
response = await graphlit.client.ingest_uri(uri, is_synchronous=True)
response.ingest_uri.id
However, the true power of Graphlit comes from the external connectors that Graphlit supports. For PDF file, a popular method for higher quality document extraction is to use Azure AI Document Intelligence.
This can smartly ingest the PDF taking into account the document’s layout including titles, paragraphs and tables. It also some common document forrmats like US Tax forms, ID documents, credit cards among others. You can integrate Azure AI Document Intelligence into your ingestion pipeline using workflows.
Let’s see how to do that:
workflow_input = WorkflowInput(
name="Azure AI Document Intelligence",
preparation=PreparationWorkflowStageInput(
jobs=[
PreparationWorkflowJobInput(
connector=FilePreparationConnectorInput(
type=FilePreparationServiceTypes.AZURE_DOCUMENT_INTELLIGENCE,
azureDocument=AzureDocumentPreparationPropertiesInput(
model=AzureDocumentIntelligenceModels.LAYOUT
)
)
)
]
)
)
response = await graphlit.client.create_workflow(input)
workflow_id = response.create_workflow.id
response = await graphlit.client.ingest_uri(
uri,
is_synchronous=True,
workflow=EntityReferenceInput(id=workflow_id)
)
First, we create a WorkflowInput object named workflow_input. This object represents the configuration for the workflow. Inside the WorkflowInput, we specify the name of the workflow as "Azure AI Document Intelligence". We then define the PreparationWorkflowStageInput.
Within the preparation stage, we specify a list of jobs using PreparationWorkflowJobInput. In this case, we have a single job. The job uses a FilePreparationConnectorInput to specify the type of file preparation service to use.
Here, we set the type to FilePreparationServiceTypes.AZURE_DOCUMENT_INTELLIGENCE. We also provide some additional properties for Azure Document Intelligence using AzureDocumentPreparationPropertiesInput.
In this example, we set the model to AzureDocumentIntelligenceModels.LAYOUT, which means we want to extract the layout information from the documents. After configuring the workflow input, we make a call to graphlit.client.create_workflow(), passing the workflow_input as a parameter. This creates the workflow in the Graphlit system.
Remember to store the ID of the newly created workflow. Finally, we use the ingest_uri method to ingest a document specified by the uri variable. We also provide the workflow_id as a reference to the workflow we created earlier.
By using Graphlit and Azure AI Document Intelligence, you can automate document processing tasks and extract valuable information from your documents efficiently. Graphlit handles all the heavy lifting for you, including document conversion, layout analysis, text extraction, and data parsing. It provides a streamlined and efficient workflow that abstracts away the complexities, allowing you to concentrate on what truly matters: developing your application and delivering value to your users.
Summary
Please email any questions on this tutorial or the Graphlit Platform to questions@graphlit.com.
For more information, you can read our Graphlit Documentation, visit our marketing site, or join our Discord community.