
Introduction
Web scraping has become an indispensable tool for extracting data from the vast expanses of data available on the internet. In this blog, we will learn how web-scraping works and the challenges of correctly extracting data from webpages. We will also look at the functionalities of various web scraping tools, including Graphlit, and compare their strengths and weaknesses in web data extraction.
How Web Scraping Works
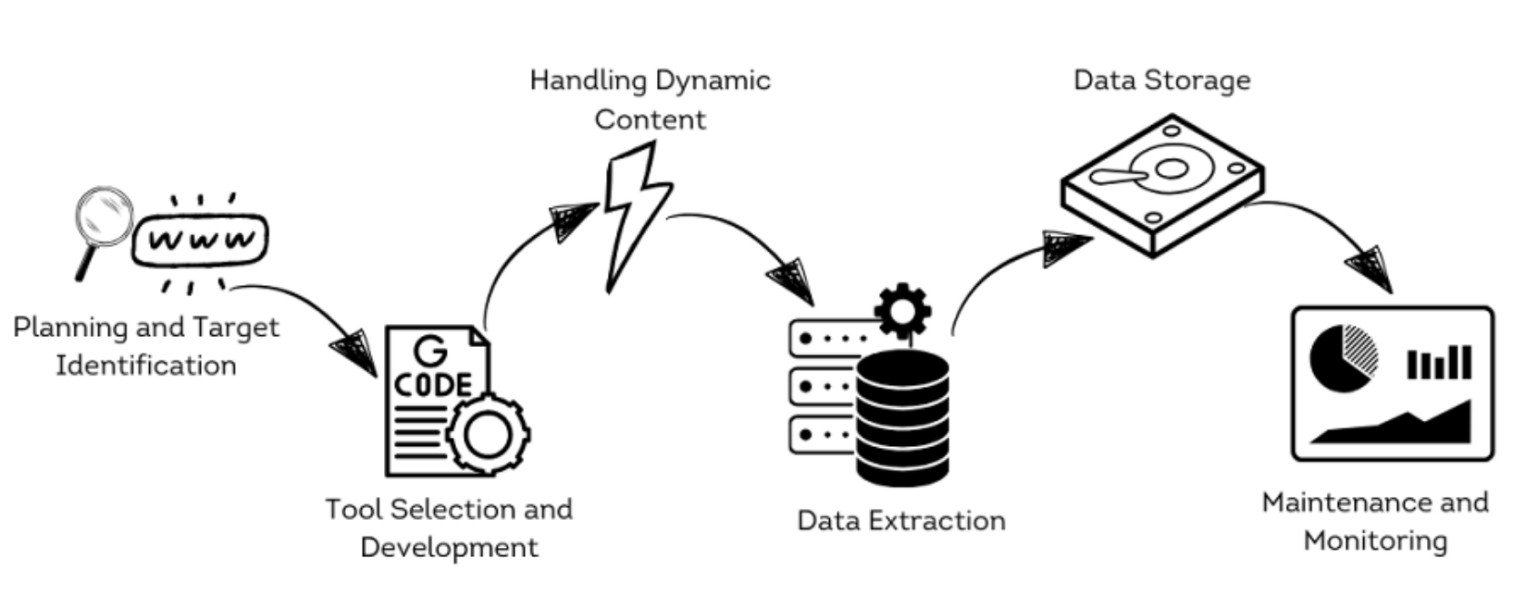
Web scraping typically follows a structured process that involves several stages, each designed to overcome the challenges mentioned above:
- Planning and Target Identification: This stage involves analyzing the website’s structure to determine the feasibility of scraping and the best tools.
- Tool Selection and Development: Choose or develop tools and scripts suited to the project's specific requirements. This could involve programming custom scrapers in Python using libraries such as Beautiful Soup or Scrapy or utilizing GUI-based tools like UIPath or Octoparse.
- Handling Dynamic Content: Headless browsers like Puppeteer or Selenium are used for dynamic sites. These browsers can render JavaScript just like a standard web browser, ensuring all dynamically loaded content is accessible.
- Data Extraction: Next we execute the scraper to parse the HTML of the web pages and extract the necessary data. This involves writing code to select the correct HTML elements and extract their contents.
- Data Processing and Storage: Store the scraped data in a structured format such as CSV, JSON, or directly into a database. This step also includes cleaning and normalizing the data to ensure consistency.
- Maintenance and Monitoring: Monitor and maintain the scraping system regularly to adapt to website structure changes or anti-scraping measures. This may involve tweaking the scraper’s logic to continue effective data extraction.
Some Popular Web Scraping Tools
Beautiful Soup: This Python library is favored for its simplicity and effectiveness in projects where complex data handling isn't required. Beautiful Soup excels in parsing HTML, making it ideal for straightforward scraping tasks. However, it lacks the integrated data processing and automation capabilities that Graphlit offers, making it less suitable for large-scale or dynamic content handling projects.
Scrapy: Another Python-based tool, Scrapy, provides a more robust framework than Beautiful Soup, supporting large-scale data extraction. It handles requests, follows links, and can export scraped data efficiently. While powerful, Scrapy requires more setup and is less user-friendly compared to Graphlit’s integrated environment, which simplifies managing extensive scraping operations.
Octoparse: As a no-code platform, Octoparse allows users without programming skills to extract data using a point-and-click interface. It’s particularly useful for non-technical users but may not offer the same level of customization or scalability as Graphlit, which can handle more complex data extraction scenarios more fluidly.
ParseHub: This tool supports scraping from JavaScript-heavy websites and can manage data extraction at scale. Its interactive tool is user-friendly, yet it might not provide the same level of integration with data analytics and storage solutions as Graphlit does, which can seamlessly transition from extraction to analysis.
Import.io: A cloud-based platform that transforms web pages into organized data, Import.io is excellent for users who need quick turnarounds without deep technical involvement. However, it does not offer the same depth of customization or the comprehensive built-in processing capabilities that Graphlit provides.
Graphlit's Approach to Web Scraping
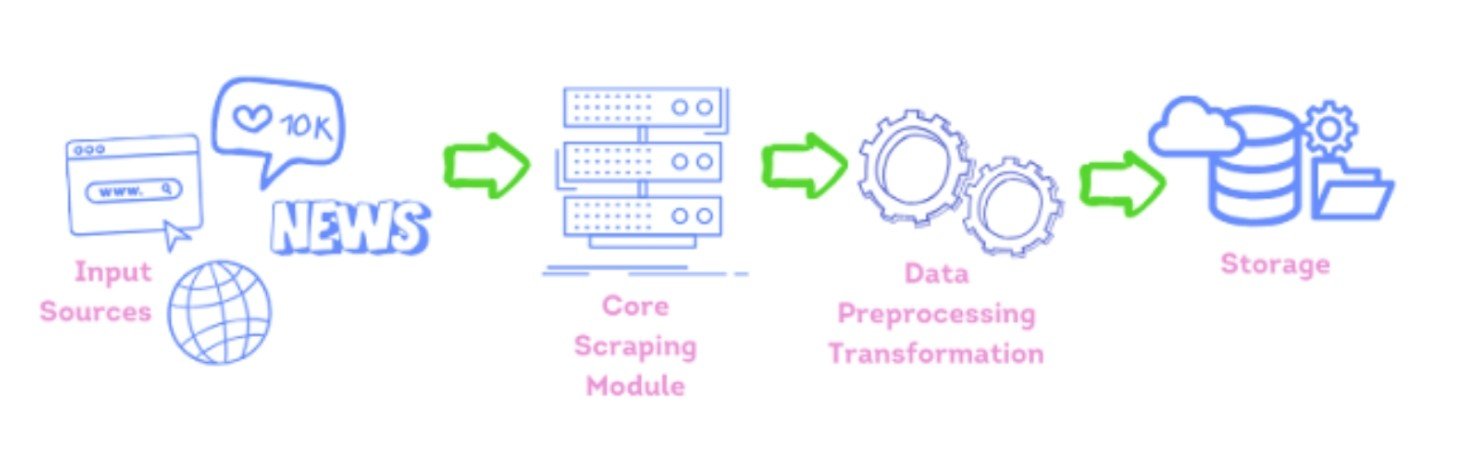
Graphlit employs a robust, end to end approach to web scraping where you do not need to worry about the structure or design of the webpage. With Graphlit, all you need is the URL of the webpage you want to ingest.
Behind the scenes, Graphlit works hard to analyze and identify the most effective ways to extract data from the website, adapting to the specific structure and challenges of each target. Graphlit can also interact with dynamic content natively, similar to headless browsers. The extracted data is automatically processed and stored in Graphlit’s vector database. Finally, Graphlit also supports scheduled data ingestions, ensuring that the data you scrape remains relevant as the target websites data gets updated.
Ingesting Webpages Using Graphlit
One of the easiest ways to ingest webpages is to use the IngestURI mutation. This mutation allows you to ingest any webpage by simply providing its URL.
Here I am trying to ingest the blog about building Autonomous LLM Agents by Lilian Weng.
Mutation:
mutation IngestUri($uri: URL!) {
ingestUri(uri: $uri) {
id
name
}
}
Variables:
{
"uri": "https://lilianweng.github.io/posts/2023-06-23-agent/"
}
Response:
{
"data": {
"ingestUri": {
"id": "5a1509b3-afdb-471e-843a-274761969fbb",
"name": "LLM Powered Autonomous Agents | Lil'Log"
}
}
}
In the above mutation, you specify the uri variable as the URL of the webpage you want to ingest. The mutation returns the id and name fields of the ingested webpage.
When building a RAG application, such as a customer support chatbot, you often need to ingest data from an entire website rather than just a single webpage. Additionally, it's crucial to keep the ingested data up to date, as the information on the website may change over time.
While the ingestUri mutation is handy for ingesting individual webpages on-demand, it may not be the most efficient approach for ingesting and maintaining data from a complete website.
Graphlit offers a solution to this problem: Graphlit Feeds. With Graphlit Feeds, you can easily ingest data from your entire website and ensure that the ingested data is regularly updated to reflect any changes made to the website's content.
Let’s see how to do that using the Data API first and then using the Python client.
Creating a Feed Using GraphQL API
Mutation:
mutation CreateFeed($feed: FeedInput!) {
createFeed(feed: $feed) {
id
name
}
}
Variables:
{
"feed": {
"web": {
"readLimit": 10,
"uri": "https://lilianweng.github.io/posts"
},
"name": "Lilian Weng Blog Feed",
"type": "WEB",
"schedulePolicy": {
"recurrenceType": "REPEAT"
}
}
}
Response:
{
"data": {
"createFeed": {
"id": "ba79a5db-e795-45a1-a7a3-184dc65aadd8",
"name": "Lilian Weng Blog Feed"
}
}
}
To create a feed, you simply need to provide a few key pieces of information: name, type, uri, readLimit and the schedule policy. The name is a descriptive name that reflects the website you are ingesting. Type is the type of feed you want to create. In this case, we're creating a web feed, so we set the type to "WEB".
Next we configure the web-specific settings for your feed which includes the URL of the website you want to ingest data from and the readLimit which sets the maximum number of pages to ingest from the website. The schedulePolicy defines how often you want the feed to update and ingest new data. You can set the recurrenceType to "REPEAT" to have the feed continuously update at regular intervals. The default interval between repeats is 15 minutes.
Creating a Feed Using Python
You can create a Graphlit Feed using Python with just a few lines of code. To get started, make sure you have the graphlit-client library installed. You can easily install it using pip:
!pip install graphlit-client -q
Once the library is installed, you can import the necessary modules and initialize the Graphlit client. You can get your Graphlit organization ID, environment ID, and JWT secret from the Graphlit portal.
from graphlit import Graphlit
graphlit = Graphlit(
organization_id="<your-org-id-here>",
environment_id="<your-env-id-here>",
jwt_secret="<your-jwt-secret-here>"
)
Next, you can create a FeedInput object to define the configuration of your feed. Set the type of the feed to FeedTypes.WEB to indicate that it's a web feed. You also need to configure the web-specific properties of the feed by providing the URL of the website you want to ingest data from and the maximum number of pages to ingest from the website.
input = FeedInput(
name=uri,
type=FeedTypes.WEB,
web=WebFeedPropertiesInput(
uri=uri,
readLimit=10
))
Finally, you can create the feed by calling the create_feed method of the Graphlit client. The create_feed method takes the FeedInput object as a parameter and returns a response containing the ID of the newly created feed. You can access the feed ID using response.create_feed.id.
response = await graphlit.client.create_feed(input)
response.create_feed.id
Graphlit Feeds simplify the process of ingesting and updating data from websites, allowing you to focus on building your application's core functionality. With just a few lines of code, you can seamlessly integrate website data into your application, enabling you to deliver up-to-date and valuable information to your users.
Summary
Please email any questions on this tutorial or the Graphlit Platform to questions@graphlit.com.
For more information, you can read our Graphlit Documentation, visit our marketing site, or join our Discord community.