In late December, Foundation Capital published their piece arguing that context graphs are the next trillion-dollar opportunity. Over the next few weeks I wrote my own response — first on the operational context layer that AI agents actually need, then on what I've been calling the event clock: the missing layer that tracks not just what is true today, but how we got there. The category name landed in a VC essay. The underlying problem has been on my desk for five years.
On April 10th, Charles Betz at Forrester published a thoughtful response of his own, arguing roughly the opposite of Foundation Capital: that context graphs aren't an invention, they're a convergence of forty years of work already underway, and the incumbents who already hold the data will win.
The frame both pieces share was on the page months before either of them weighed in. Back in October 2025 — two months before Foundation Capital, six months before Betz — Matt Brown at Matrix Partners published "Your data model is your destiny". He never names any of this debate. He just draws the line I want to draw. His argument: when AI commoditizes code, technical execution is table stakes. The startup's data model — the load-bearing choice about which parts of reality matter most in how the product represents the world — is the foundation of the moat. Slack's persistent channels. Notion's blocks. ServiceNow's connected services. Each one a non-obvious data model bet that compounded into a category. Each one impossible to copy without rebuilding from scratch.
Brown's post predates this entire debate and already settles it. Foundation Capital is right that this category matters. Betz is right that nobody invented it yesterday. Brown gets at why both of those can be true and the incumbents Betz names still don't win the next round.
Where Betz is right
The convergence is real. The ideas underneath context graphs — knowledge graphs, ontologies, identity resolution, temporal modeling, structured representations of organizational knowledge — have been around for decades. The semantic web crowd has been working on identity and entity resolution since the early 2000s. Process mining reconstructed workflows from event logs more than a decade ago. A category name landing in a VC essay in late 2025 doesn't mean the underlying problem is new. Anyone claiming to have invented this is selling you something.
He's also right about fidelity. Most attempts at organizational memory rot. Forms go stale. Inventories drift. Maps stop matching the territory. The cautionary tale he leans on is the CMDB — the Configuration Management Database, IT operations' attempt at a single inventory of every server, application, and dependency in the estate. CMDBs rotted for a specific reason: they were manual write surfaces nobody had time to maintain, in a discipline where the cost of error got distributed across operations teams who couldn't push back. Adding AI to a low-fidelity foundation doesn't make agents smarter. It makes them confidently wrong. Governance, provenance, lifecycle, the discipline of keeping the picture honest — these aren't features bolted on at the end. They're the product, or they're nothing.
And he's right that capturing why something was decided is the genuinely new contribution. Knowing what's true today is table stakes. Knowing how we got there — what was considered, what was rejected, what was promised, what we learned — is the layer that makes agents useful instead of dangerous.
Convergence, real. Fidelity, hard. Decision capture, the actual frontier. We agree on all of that.
Where I disagree
His conclusion is that this favors incumbents. ServiceNow, Atlassian, Palantir — they hold the data, so they're best positioned to extend their existing graphs into the decision layer. Startups are arriving late and building on top of forty years of work they don't understand.
This gets the situation backwards, for two reasons.
First, the data the incumbents hold isn't the data that matters. When I talk to companies about what they actually need an AI agent to know, almost none of it lives in a service management ticket or an asset inventory. It lives in the back-and-forth with a customer over three months of email. In the meeting where the deal terms got reshaped. In the Slack thread where engineering pushed back on a roadmap commitment. In CRM notes, call transcripts, document revisions, the project channel, the shared drive. Knowledge work is multimodal, multi-source, and almost entirely outside the systems the incumbents he names were built to hold.
Saying ServiceNow wins because they have a graph of IT assets is like saying Oracle should have won search because they had a database. The graph that matters for an organizational AI agent isn't a system-of-record graph. It's a memory of the business — people, customers, conversations, commitments, rationale. Nobody owns that today, because no system was designed to.
Second, Brown's frame nails the part that doesn't get talked about. The incumbents already have a data model. That data model is their product. Salesforce is opinionated about what a customer is and how relationships hang off it. ServiceNow is opinionated about what an incident is and what service map it sits on. Notion is opinionated about pages and blocks and databases. Atlassian is opinionated about issues, projects, and teams. These opinions are why customers bought them. They're also why extending them into a true context graph is much harder than it looks.
Those data model choices were how those companies won their original categories. Slack's persistent channels were a data model bet, not a feature. ServiceNow's connected services were a data model bet, not a feature. Notion's blocks were a data model bet. The bets compounded into category dominance. And now the cost of replacing them is roughly the cost of becoming a different company.
Notion just made this case for me. Last week they announced their Developer Platform, with a feature called Workers that lets you sync any data source — Salesforce, Zendesk, Postgres, anything with an API — into Notion databases. Their pitch: "now your agents can read it, your team can see it, and everyone is working from the same shared, trusted context." Read it again. Their answer to the fragmented-context problem is to bring everyone's data into Notion databases. The blocks-and-databases model didn't change. The world is still expected to fit into Notion's shape, just with more import pipes attached. It's a real step forward for Notion users. But anything that doesn't fit — a meeting recording, a video, a call transcript with five participants, a thread that crosses six tools — still has to be flattened into a row in a Notion database to participate.
Same pattern everywhere. When Salesforce adds AI, every piece of context has to become a Salesforce object or a field on one. When ServiceNow extends into context engine territory, the context has to fit the service-map model. They can extend their graphs, but only in the shape of what they already are. Anything that doesn't fit — and most of organizational reality doesn't — gets squeezed in awkwardly, lives outside the graph, or doesn't get captured at all.
This is the part Betz misses. The graph isn't just data. It's a data model, and the data model carries an opinion about what the world looks like. The incumbents' opinions were formed in a different era for a different job. So we'll see incumbents grafting context onto their existing shapes and calling it a context graph, when what they've really shipped is a slightly smarter version of their existing system.
That's not a context graph for the business. That's a context graph for the application.
What we built instead
For the last five years, we've been working on one architectural question — the exact question Brown's framework asks every founder to answer. What's the atomic unit of work for an AI agent operating across an entire organization? What data model do you need underneath the agent if you want it to reason across everything that organization does, regardless of where the work happens?
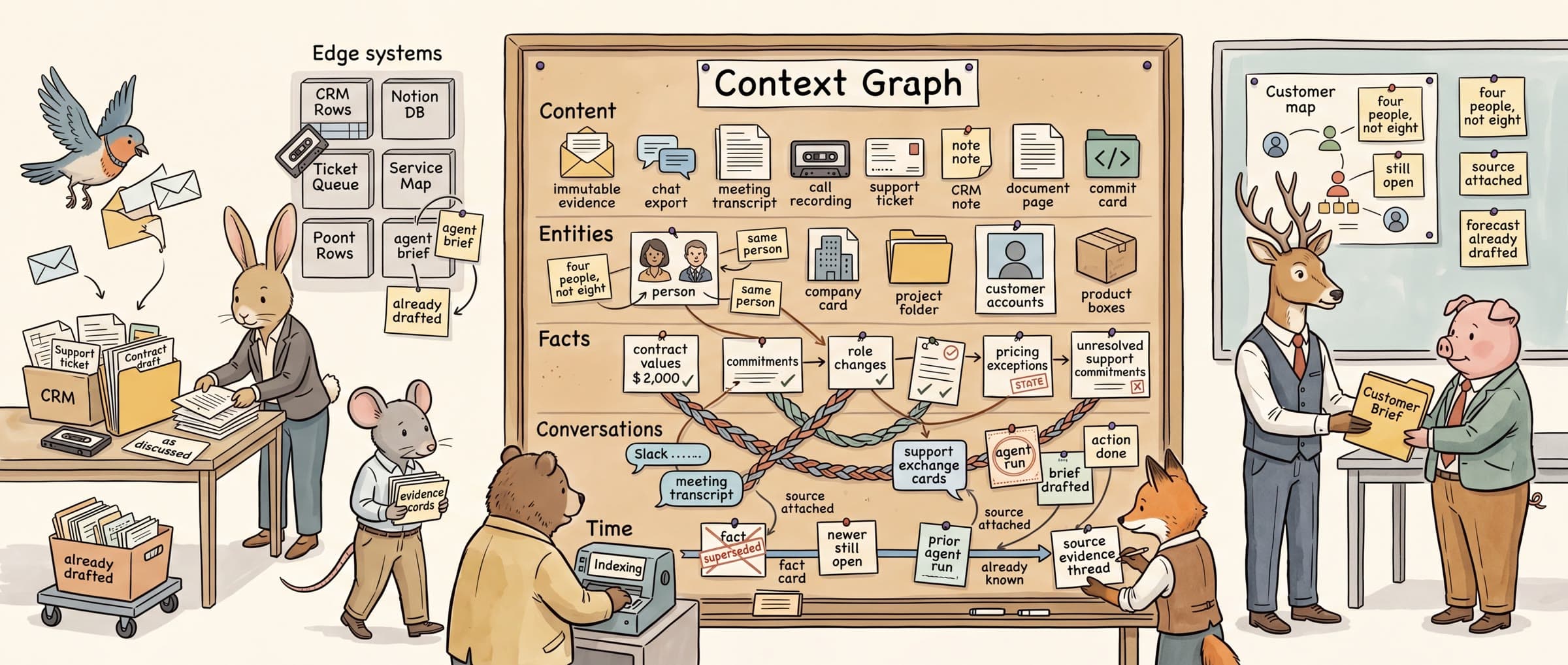
The answer is four layers. They're worth describing because they're load-bearing for the rest of this argument.
Content is the immutable evidence layer. Every email, message, meeting recording, document, ticket, commit, page, post, file — ingested with its original structure preserved, not flattened into text for embedding. Content doesn't change. It's the source of truth, and its provenance is permanent.
Entities are the identity layer. The same person showing up in Slack, email, a CRM record, a calendar invite, and a meeting transcript is one entity, resolved across sources, aligned with open standards like Schema.org. Same for companies, products, places, projects, events. The entity layer is the spine that makes everything else queryable.
Facts are the assertions about the world, with validity periods, sources, and status. "This deal is at $400K." "This person changed roles in February." "This commitment was made on a call last Tuesday." Facts are first-class data. They have provenance back to the content they came from. They have time. They can be superseded. They can be wrong, and the system has to know they can be wrong.
Conversations are the connective tissue. Both human chats — Slack threads, iMessage, support exchanges, the back-and-forth that produced a decision — and agent runs, where an agent already answered a question, made a recommendation, drafted a brief, or took an action on someone's behalf. Conversations are how the rest of the graph gets stitched together historically. They link a fact to the discussion that produced it, an entity to who's been talking about them, content to what we already concluded about it. Without conversations, the graph tells you what's true. With them, it tells you how the organization actually came to think so — and what's already been done about it.
These four layers — content, entities, facts, conversations — bind into a graph that's continuously derived from ingested reality, not curated by hand into forms. Indexed across multiple axes at once: full-text, vector, graph relationships, time, geospatial. Source-agnostic. Schema-stable. Designed from day one for the job AI agents actually need it to do.
This is the data model bet, in Brown's sense of the term. It isn't downstream of any application's worldview. It doesn't assume reality fits into pages and databases, or accounts and opportunities, or incidents and CIs. It assumes reality is multimodal content about resolved entities, accumulating facts over time, threaded together by the conversations — human and agent — that move the work forward.
Five years of work has gone into the parts that aren't sexy on a landing page: identity resolution that actually works across messy real-world data, temporal modeling that handles late-arriving and superseded facts, ingestion pipelines that preserve structure rather than flattening it, conversation history as first-class data, indexing strategies that let you ask questions spanning text, vectors, relationships, and time in a single query. None of this gets replicated by adding a context feature to an existing application.
A scenario, to make this concrete
Sanitized, but representative of work we see all the time.
A mid-market SaaS company has a renewal coming up with a strategic customer. The account team wants an AI agent to help prep. Here's what the agent has to reason over:
- Six months of email between the account team and four contacts at the customer, including a thread where the customer's VP of Engineering pushed back on a missing feature.
- A dozen meeting recordings — discovery calls, QBRs, a steering committee, two escalations. The first two contacts have since left the company.
- Slack messages in a shared channel between customer success and the customer's admin, where a workaround was agreed to in March.
- CRM records showing the opportunity, the renewal forecast, and a contract value edited four times.
- Three Notion pages where the account team has been keeping running notes, plus a Google Doc with a draft expansion proposal.
- Two support tickets, one of which surfaced a commitment from the CSM that doesn't appear anywhere else.
- A pricing exception approved over a phone call between the two CFOs, with a one-line follow-up email that says "as discussed."
- Three prior agent runs from the last quarter — a deal-prep brief from before the QBR, an escalation triage when the customer mentioned "legal," and a renewal forecast the agent already drafted last week.
What does the agent need to know to be useful?
That the four customer contacts are four people, not eight (two appear under different email addresses, one shows up with a maiden name in early correspondence). That the VP of Engineering is the technical decision-maker, even though she's been cc'd on fewer threads than the procurement contact. That the contract value is $480K as of last week, not $520K from the January draft, and the change traces back to a specific call. That the workaround agreed to in March is still in place. That the commitment from the support ticket is unresolved. That "as discussed" refers to a specific phone conversation, and what was discussed. That the renewal forecast it drafted last week already had a $480K number in it, sourced from the same call.
None of that lives in any one system. The CRM has the opportunity but not the rationale. Email has the rationale but not who's who. The meetings have texture but no link to contract values. Slack is invisible to the CRM. Notion is invisible to everything. The phone call only exists as a one-line email that needs the rest of the graph to be interpretable. And the agent's own prior runs — what it already figured out, what it already recommended — sit in yet another place entirely.
This is the work. And it's not work an AI model does, no matter how capable the model gets. It's work the layer underneath the model does, before the model is ever invoked. Resolving four contacts to four entities. Binding contract-value facts to their source emails and calls with timestamps. Tracking which commitments are open, which are superseded, which are still in force. Holding meeting transcripts as first-class evidence. Holding prior agent runs as first-class context, so the agent doesn't re-derive what it already knew.
That work is the context graph. Not the application built on top of it. Not the AI feature next to it. The graph itself.
And notice what's not in the picture: a CMDB, an asset inventory, a service topology, an incident table, a Notion database. The incumbents Betz names are building graphs of a different domain entirely. The Notion answer would be to import the CRM, the meeting notes, and the support tickets into Notion databases and call it shared context. But meeting recordings don't fit in a database row. Four-people-not-eight resolution doesn't happen at import time. "As discussed" doesn't get interpreted by a sync pipeline. And prior agent runs aren't a Notion concept at all. This scenario isn't an edge case. This is what knowledge work looks like.
The fidelity argument, taken seriously
Betz is right that fidelity is where most of these efforts will die. The CMDB cautionary tale is fair — those rotted because they were manual write surfaces nobody had time to maintain, in a discipline where the cost of error got distributed across operations teams who couldn't push back.
The fidelity curve looks different when the graph is derived from ingested reality instead of typed into forms. If a person changes roles and that change shows up in three emails, two meeting transcripts, and a CRM update, the graph reflects it. If a fact gets superseded, the new fact carries the provenance and the timestamp, and the old one moves into history rather than getting overwritten. If an entity gets merged or split, the content trail stays intact.
That doesn't make the problem disappear. Identity resolution is hard. Conflicting facts have to be reconciled. Provenance can be ambiguous. The system still needs investment, governance, humans in the loop for the hard cases. We don't pretend otherwise. But the structural cause of CMDB rot — humans typing into forms nobody has time to keep current — isn't the failure mode for a graph derived continuously from the work itself.
Where I agree with Betz most strongly: the startups who treat governance as a customer problem will fail. Provenance, lifecycle, access control, versioning, the ability to say "this entity is retired" or "this fact is no longer valid" — these are first-class product capabilities, not implementation details. We've been treating them that way. Anyone who isn't won't survive contact with a real enterprise.
The dark matter is the point
Betz ends his piece with a postscript that I think is the most important paragraph he wrote, and he undersells it. He acknowledges that the highest-value decisions in most organizations happen in phone calls, meetings, hallway conversations, and threads — and that this reasoning is "dark matter" unless organizations capture everything.
Brown uses the same phrase — "dark matter" — for the data model itself: the load-bearing choice you can't see in a feature list but that holds the entire product together. Both readings are right, and they're connected. The dark matter of organizational reasoning lives in unstructured human communication. The dark matter of the company that wins this category is the data model designed to hold it.
The technical question of whether unstructured communication can be captured shifted years ago. Meeting capture is mainstream. Transcription is commoditized. Email and chat are instrumented. The hard question isn't "can we get the data" anymore. It's "can we resolve it" — can we tie a sentence in a meeting transcript to the same person, the same deal, the same commitment, the same timeline as the email thread from last month, the CRM record from yesterday, and the agent's own run from last week. That's the work. That's where the moat lives. And it's exactly what a graph designed for ingestion-first, entity-resolved, time-aware, conversation-threaded reasoning is built to do.
The incumbents Betz names aren't built for that work. ServiceNow isn't going to be the place where your customer call transcripts live. Salesforce isn't going to hold your meeting recordings as first-class evidence. Notion isn't going to resolve the same person across your CRM, your email, your calendar, and your Slack — it's going to ask you to sync them into a database and call it solved. They might each add a feature that gestures at it. None of them can rebuild their data model around it without becoming a different company.
The dark matter Betz writes off as too hard to capture is exactly the substrate where the next generation of organizational AI actually has to operate. Not because someone wrote a manifesto about it. Because that's where the work is.
Where this leaves us
Convergence is real. Foundation Capital is right that this category matters. Betz is right that nobody should pretend it was invented yesterday. Brown was right last October, before either of them weighed in: when AI commoditizes code, the data model is the moat — and the incumbents who already won their categories did it on data model bets that now lock them into the shape they chose.
The context graph that actually works for AI agents isn't an extension of the IT estate. It isn't a sync pipeline into a workspace database. It isn't a feature you add to the application you already bought. It's organizational memory — content, entities, facts, conversations, all over time — built on a data model designed for that job, ingesting from wherever the work happens, agnostic to the system of record. The shape matters. The shape is the product.
We've been building this for five years. Through three category names. Through the RAG hype, the agent hype, the memory hype, and now the context graph hype. The names changed. The architecture didn't. We made the bet early that the data model was load-bearing, and we've spent five years compounding on that bet. Identity resolution, temporal modeling, multimodal ingestion, fact provenance, conversation history, governance — the parts that don't show up on a landing page but determine whether anything else works.
The incumbents have data. We have the right shape for it. Brown's piece is the cleanest articulation I've read of why that distinction matters. Over the next two years, it's going to matter more than anyone in this conversation currently expects.