
This is part of a three-part series exploring the emerging context graph infrastructure layer. We start with why agents need operational context before they can capture decision traces, then dive into the technical architecture of building temporal fact stores, and finally tackle the ontology question that's dividing the industry. Together, these pieces form a complete picture of what it actually takes to build the context layer that enterprise AI demands.
A fascinating conversation has been unfolding this week about the future of enterprise AI infrastructure.
On December 22nd, Foundation Capital published "Context Graphs: AI's Trillion-Dollar Opportunity", arguing that the next trillion-dollar platforms won't be built by adding AI to existing systems of record—they'll be built by capturing decision traces, the reasoning that connects data to action.
I wrote a response on December 24th, agreeing with their thesis while adding what I saw as a missing layer: you can't capture decision traces without first solving the operational context problem. Identity resolution, entity relationships, temporal state—the substrate that makes decision graphs possible.
Today, PlayerZero CEO Animesh Koratana published a deeper followup expanding on how to actually build a context graph. The piece introduces compelling concepts: the "two clocks" problem, agents as informed walkers, and context graphs as organizational world models.
These ideas resonate—because we've been building exactly this infrastructure at Graphlit since 2021. The theory is catching up to what production systems require. Here's what we've learned from actually building context graphs, where the framing is exactly right, and where it needs refinement.
The Two Clocks: The Clearest Framing Yet
The PlayerZero piece introduces a metaphor that crystallizes the problem:
"Every system has a state clock—what's true right now—and an event clock—what happened, in what order, with what reasoning. We've built elaborate infrastructure for the state clock. The event clock barely exists."
This is the clearest articulation of the gap I've seen.
The example they give is perfect: "The config file says timeout=30s. It used to say timeout=5s. Someone tripled it. Why? The git blame shows who. The reasoning is gone."
This pattern is everywhere:
- The CRM says "closed lost" but doesn't say you were the second choice
- The treatment plan says "switched to Drug B" but doesn't say Drug A was working until insurance stopped covering it
- The contract says 60-day termination but doesn't say the client pushed for 30 and you traded it for the liability cap
We've built trillion-dollar infrastructure for what's true now. Almost nothing for why it became true.
The event clock—the reasoning connecting observations to actions—was never treated as data. It lived in heads, Slack threads, meetings that weren't recorded.
Time Is Just One Axis
But here's where I'd extend the framing: time isn't the only missing dimension.
When I started building Graphlit in 2021, the core vision was indexing unstructured data in time and space—a multi-axis index where events could be attributed to:
- Timeline: When did this happen? When did it become true? When did it stop being true?
- Geospatial coordinates: Where did this happen? What location is this relevant to?
- Full-text search: What words and phrases appear in the content?
- Vector embeddings: What is this semantically similar to?
- Graph relationships: How does this connect to other entities?
Most systems pick one or two of these axes. Search engines do full-text. Vector databases do embeddings. Knowledge graphs do relationships. Time-series databases do temporal. GIS systems do geospatial.
But organizational knowledge exists across all these dimensions simultaneously. A sales meeting happened at a specific time, in a specific city, about a specific account, with semantic content that relates to other conversations, connected to people and products in a relationship graph.
The "two clocks" framing captures the temporal gap. The full picture is a multi-dimensional index where time is one axis among several—and where all axes are queryable together.
This is what we've been building. Facts have validAt and invalidAt for temporal queries. Content has location metadata for geospatial filtering. Everything has embeddings for semantic search. Entities and relationships form the graph layer. And you can combine them: "What did we discuss about Acme Corp in meetings held in New York during Q3?"
Three Layers, Not Two
Here's where I want to extend the framing. The two-clock model is right, but the implementation requires three distinct layers:
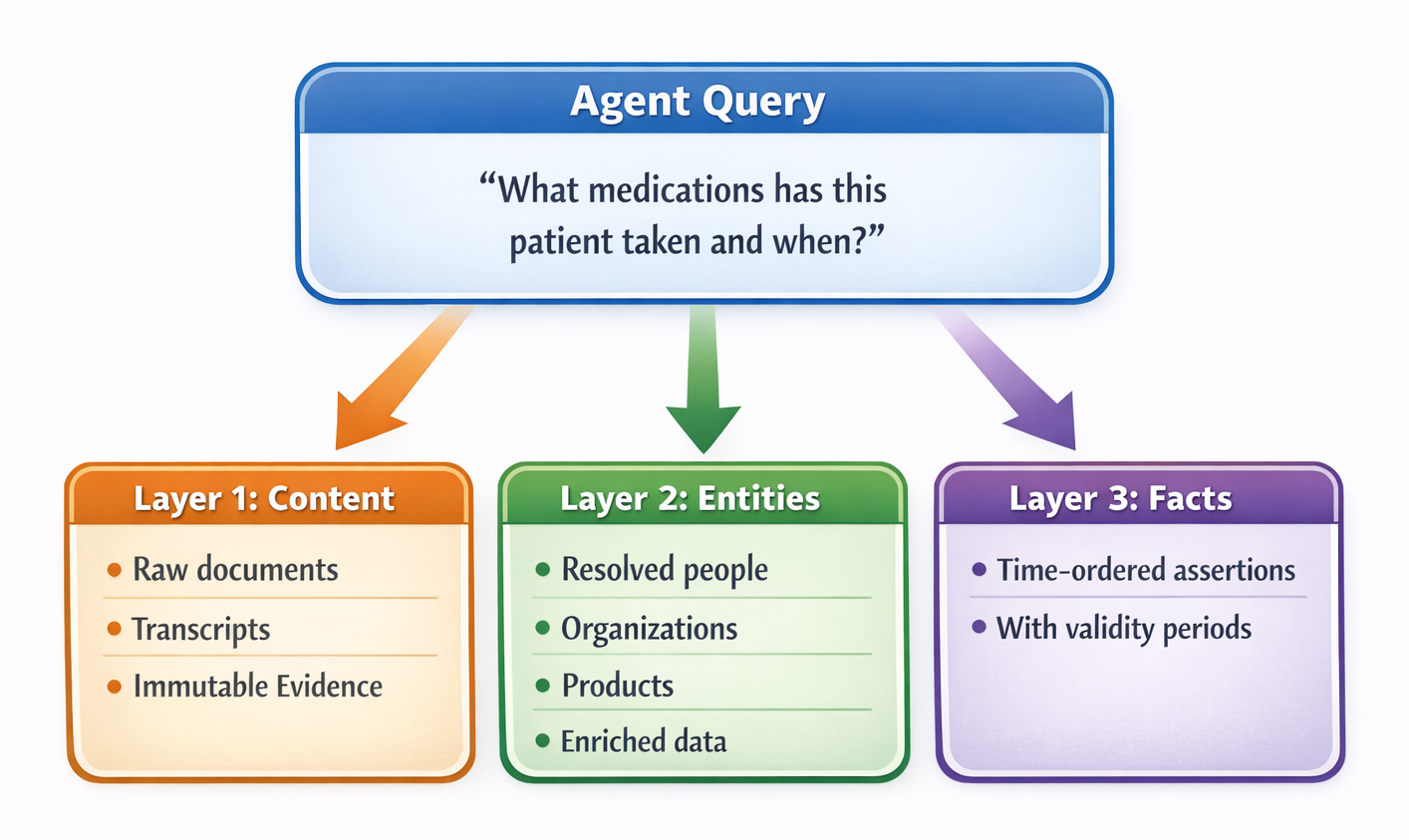
Content is the state clock—immutable source documents, the evidence trail. Content is never edited, merged, or deleted by resolution. It's the canonical record of what was captured.
Entities are what content mentions—people, organizations, places, products, events. This is where identity resolution happens. "Sarah Chen" in an email, "S. Chen" in a meeting transcript, and "@sarah" in Slack are the same person. Without entity resolution, you can't reason about actors.
Facts are what content asserts—temporal claims about the world. This is the event clock. Not just "the patient takes Drug A" but "the patient started Drug A on March 15, 2024" and "the patient stopped Drug A on August 3, 2024 when insurance coverage ended."
Each layer is progressively more structured. Content is raw evidence. Entities add identity. Facts add temporality and assertion.
Facts as First-Class Data
Here's what we've learned from building this: facts need to be first-class entities, not just derived metadata.
A fact in our system has:
- Text: The assertion itself ("Paula works at Microsoft as Principal Engineer")
- validAt: When did this become true? (January 10, 2024)
- invalidAt: When did it stop being true? (null—still current)
- Status: Canonical, Superseded, Corroborated, Synthesized
- Mentions: Which entities does this fact reference? (Paula → Person, Microsoft → Organization)
- Content: What source document is this derived from?
This structure captures temporal validity natively. When you query "What's Paula's current employer?", you don't search for recent documents and hope the LLM figures it out. You query facts where invalidAt is null.
When you query "Where did Paula work in 2022?", you filter facts where validAt <= 2022 and invalidAt > 2022 (or null at the time).
The event clock becomes queryable data, not reconstructed reasoning.
Synthesized Facts: The Key Insight
The PlayerZero piece describes context graphs as "world models" that enable simulation. This is exactly right, and it points to something important: facts derived from multiple sources.
Consider three source facts:
- "Paula works at Google" (validAt: 2020-01-15)
- "Paula is a Senior Engineer at Google" (validAt: 2022-06-01)
- "Paula joined Microsoft as Principal Engineer" (validAt: 2024-03-15)
From these, you can synthesize:
- "Paula worked at Google from January 2020 to March 2024"
- "Paula was promoted to Senior Engineer at Google in June 2022"
These synthesized facts have a different status—they're derived, not directly observed. But they're often more useful for reasoning. They tell you duration, not just point-in-time snapshots.
Synthesized facts also carry evidence chains. Each one points back to the source facts it was derived from, which point back to the original content. The audit trail is preserved.
This is what makes fact resolution hard—and valuable. Determining what's currently true, what was historically true, and what can be inferred from multiple observations requires judgment. We're building this with LLM-powered resolution, using the model to cluster similar facts, identify supersession relationships, and synthesize timeline facts from scattered observations.
World Models Without Continual Learning
A note on terminology: "world model" here means something specific—borrowed from reinforcement learning, it's a learned representation of how an environment behaves, enabling prediction and simulation. It's not the LLM itself, but the structured knowledge the LLM reasons over. The context graph is the world model. The LLM is the reasoning engine that queries it.
This week's discussion surfaced an important observation about continual learning:
"The path to economically transformative AI might not require solving continual learning. It might require building world models that let static models behave as if they're learning, through expanding evidence bases and inference-time compute."
This is exactly right, and it describes what fact resolution enables. The model doesn't need to update its weights to "learn" that Paula now works at Microsoft. The world model—the accumulated, resolved facts—captures that knowledge. At inference time, the model reasons over current facts, not stale training data.
The context graph becomes external memory that makes static models contextually intelligent. Each resolved fact, each synthesized timeline, each entity relationship expands what the model can reason about—without retraining. This is the insight that connects everything: the event clock isn't just historical record-keeping. It's how you give agents memory that actually works.
Agents Need a Map, Not Just Footprints
There's one area where I'd refine the framing: the relationship between agents and the graphs they traverse.
The "agents as informed walkers" concept is essentially describing what we'd call agentic RAG—a reasoning LLM orchestrating tool calls through an agent harness that manages the workflow loop and context window. Each "walk" is a trajectory through tools and data sources: retrieve some context, reason about it, call another tool, retrieve more context, synthesize an answer.
The insight that these trajectories encode organizational structure is compelling. The argument is that agent runs through organizational state space are a form of graph embedding—discovering ontology through use rather than specification:
"The ontology emerges from walks. Entities appearing repeatedly are entities that matter. Relationships traversed are relationships that are real."
This is intellectually elegant, but I think it inverts the practical order of operations.
You can't wait for thousands of agentic RAG runs to "discover" that Sarah Chen is a person who works at Acme Corp. You need to know that before agents start reasoning. Otherwise every agent trajectory is fighting the identity resolution problem anew—and you're paying for that confusion in tokens, latency, and errors.
The node2vec analogy actually illustrates this. Node2vec works because you're exploring a known graph structure—the algorithm learns embeddings from walk patterns over existing edges. It doesn't discover nodes and edges from scratch. The graph must exist first.
Agentic workflows operate the same way. The agent harness orchestrates tool calls over a pre-built map. The map is operational context: resolved entities, established relationships, temporal state. Build the map first, then agents walk it effectively.
The "agents as walkers" framing works beautifully for extending the graph—discovering new relationships, validating existing ones, surfacing patterns humans missed. But it's not how you bootstrap. That requires intentional infrastructure, built before agents arrive.
Dynamic Discovery: The Missing Piece
Building the context graph is one problem. Accessing it at scale is another.
As agents connect to more data sources, you can't stuff everything into context upfront. Anthropic's recent work on tool discovery shows where this is heading: 50+ tools can consume 55K+ tokens before a conversation even starts. Their solution—dynamic tool search—improved accuracy from 49% to 74% in testing.
We hit the same problem and arrived at the same pattern. Our MCP server exposes three meta-tools (search_tools, describe_tools, execute_tool) instead of 20+ individual tools. Agents discover what they need through semantic search, load only relevant definitions, then execute. Same pattern Anthropic just released as beta—we've been running it in production.
The deeper point: this pattern applies to context, not just tools. You don't want to stuff an entire knowledge graph into the context window any more than you want to stuff 100 tool definitions.
An agent working on a customer issue doesn't need your entire knowledge graph. It needs the facts about this customer, the entities involved in this account, the content relevant to this problem. Our MCP server exposes exactly this: retrieveFacts, queryEntities, content search—all scoped to what the agent actually needs.
Set up once, use everywhere. Connect your sources to Graphlit, and the same context layer is available to Cursor, Claude Desktop, custom orchestration, whatever comes next. The context graph is the hard part. Standardized access is what makes it usable.
What We're Building
We're shipping Facts mode in Graphlit Studio the first week of 2026—a table view for browsing, filtering, and searching extracted facts, plus a graph view showing how facts connect to entities. It's the first piece of making the event clock visible and queryable.
Here's where we're headed in 2026:
Shipped:
- Fact extraction from multimodal content (documents, transcripts, emails)
- Facts mode in Graphlit Studio with filtering by status, date range, search
- Entity mentions on facts (connecting assertions to resolved people, orgs, products)
In Progress:
- Fact→Entity relationship edges (filter facts by entity, same UX as content filtering)
- Graph visualization for facts (see how assertions connect to entities)
Coming:
- Fact resolution with LLM (determining canonical vs. superseded, synthesizing timeline facts)
retrieveFactsas a first-class agent tool (semantic search over assertions, not just documents)- CRM integration as the entity spine (accounts, contacts, deals as the backbone for organizational context)
The vision Foundation Capital and PlayerZero articulate isn't just achievable—we're building it. The sequence matters: operational context first (identity resolution, entity extraction, temporal modeling), then the event clock on top (facts with validity periods, resolution to determine current truth, synthesis to derive timeline knowledge). Skip the foundation and you're building on sand.
The Path Forward: 2026 and Beyond
Three principles from this week's conversation will define how context infrastructure evolves:
1. The two clocks problem is real—and solvable. We've built trillion-dollar infrastructure for state and almost nothing for reasoning. The event clock has to be captured for the first time. This is an infrastructure problem, not a research problem.
2. Facts are the unit of the event clock. Not documents, not embeddings, not chat transcripts. Temporal assertions with validity periods, connected to resolved entities, traceable to source evidence. Make facts queryable and you make reasoning auditable.
3. Resolution is where world models emerge. Determining what's currently true from historical assertions, synthesizing timeline facts from scattered observations, enabling "what if" queries over organizational state—this is where context graphs become genuinely useful. This is where agents stop being clever autocomplete and start being organizational intelligence.
The companies that build this infrastructure will have something qualitatively different. Not agents that complete tasks—organizational intelligence that compounds. That reasons from accumulated context rather than starting from scratch every time. That learns without retraining, through expanding world models at inference time.
That's what we're building at Graphlit. The event clock isn't just a metaphor. It's an architecture. And 2026 is the year it becomes operational.
The Foundation Capital piece "Context Graphs: AI's Trillion-Dollar Opportunity" and Animesh Koratana's followup on building context graphs are both worth reading in full. This is an important conversation about infrastructure, and I'm glad it's happening.
Learn more at graphlit.com.