Bring knowledge to your AI apps
Integrate your data with LLMs
in minutes, not weeks
Bring knowledge to your AI apps
Integrate your data with LLMs
in minutes, not weeks
Bring knowledge to your AI apps
Integrate your data with LLMs
in minutes, not weeks
from graphlit import Graphlit
from graphlit_api import *
await graphlit.client.ingest_uri(
uri="https://www.graphlit.com"
)
response = await graphlit.client.prompt_conversation(
prompt="How can Graphlit accelerate my Generative AI app development?"
)
message = response.prompt_conversation.message.message
print(message)from graphlit import Graphlit
from graphlit_api import *
await graphlit.client.ingest_uri(
uri="https://www.graphlit.com"
)
response = await graphlit.client.prompt_conversation(
prompt="How can Graphlit accelerate my
Generative AI app development?"
)
message = response.prompt_conversation.message.message
print(message)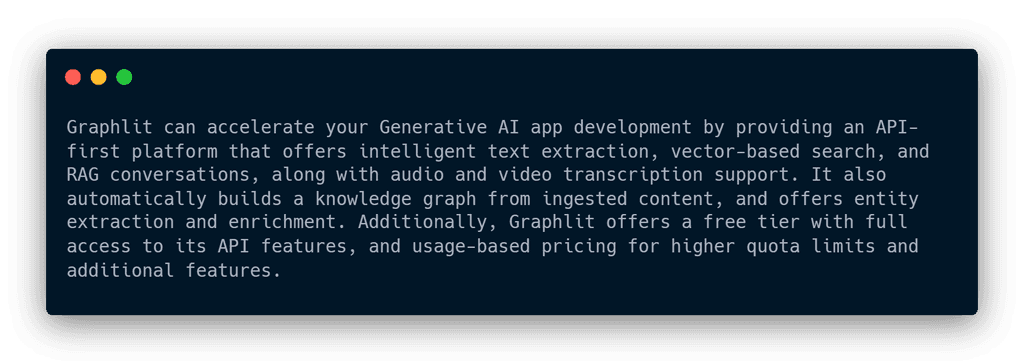
Try Graphlit for yourself, for free:
Try Graphlit for yourself, for free:



















What can I ingest?
Ingest from any data source such as:
Web sites, cloud storage, SharePoint, podcasts,
Jira, Notion, YouTube, email or Slack
Ingest any unstructured data format such as:
documents, audio, video, or images
AUTOMATED ETL FOR LLMs
AUTOMATED ETL FOR LLMs
AUTOMATED ETL FOR LLMs
Unstructured data ingestion
Unstructured data ingestion
Unstructured data ingestion
Data feeds for continual ingestion
Extract text and tables from documents and images with OCR and LLMs
Configure automated content workflows
Extract metadata, named entities and structured data from your content
Web scraping and screenshots
Enrich data with external APIs, such as Wikipedia and Crunchbase
from graphlit import Graphlit
from graphlit_api import *
input = FeedInput(
name=f"{account-name}: {container-name}",
type=FeedTypes.SITE,
site=SiteFeedPropertiesInput(
type=FeedServiceTypes.AZURE_BLOB,
isRecursive=True,
azureBlob=AzureBlobFeedPropertiesInput(
accountName="{account-name}",
containerName="{container-name}",
storageAccessKey="{storage-key}",
prefix="{prefix}"
)
),
workflow=EntityReferenceInput(
id="{workflow-id}"
)
)
response = await graphlit.client.create_feed(input)from graphlit import Graphlit
from graphlit_api import *
input = FeedInput(
name=f"{account-name}: {container-name}",
type=FeedTypes.SITE,
site=SiteFeedPropertiesInput(
type=FeedServiceTypes.AZURE_BLOB,
isRecursive=True,
azureBlob=AzureBlobFeedPropertiesInput(
accountName="{account-name}",
containerName="{container-name}",
storageAccessKey="{storage-key}",
prefix="{prefix}"
)
),
workflow=EntityReferenceInput(
id="{workflow-id}"
)
)
response = await graphlit.client.create_feed(input)from graphlit import Graphlit
from graphlit_api import *
input = WorkflowInput(
name="Azure AI Document Intelligence",
preparation=PreparationWorkflowStageInput(
jobs=[
PreparationWorkflowJobInput(
connector=FilePreparationConnectorInput(
type=FilePreparationServiceTypes.AZURE_DOCUMENT_INTELLIGENCE,
azureDocument=AzureDocumentPreparationPropertiesInput(
model=AzureDocumentIntelligenceModels.LAYOUT
)
)
)
]
)
)
response = await graphlit.client.create_workflow(input)from graphlit import Graphlit
from graphlit_api import *
input = WorkflowInput(
name="Azure AI Document Intelligence",
preparation=PreparationWorkflowStageInput(
jobs=[
PreparationWorkflowJobInput(
connector=FilePreparationConnectorInput(
type=FilePreparationServiceTypes.AZURE_DOCUMENT_INTELLIGENCE,
azureDocument=AzureDocumentPreparationPropertiesInput(
model=AzureDocumentIntelligenceModels.LAYOUT
)
)
)
]
)
)
response = await graphlit.client.create_workflow(input)RAG-AS-A-Service
RAG-AS-A-Service
RAG-AS-A-Service
What else?
What else?
What else?
RAG Ready: Intelligent text extraction and chunking, built-in vector embeddings and conversation history
Semantic Search: Vector-based search, including metadata filtering
Content Creation: Automated text and transcript summarization, social media post generation, long-form content creation
ANY CONTENT, ANY FORMAT
ANY CONTENT, ANY FORMAT
ANY CONTENT, ANY FORMAT
Multimodal ready
Multimodal ready
Multimodal ready
Integrated with Large Multimodal Models (LMMs) including OpenAI GPT-4 Vision
Automatic audio transcription
Generate image descriptions with visual object detection
Similarity search via image embeddings
from graphlit import Graphlit
from graphlit_api import *
response = await graphlit.client.query_contents(
filter=ContentFilter(
search_type=VECTOR,
search="Unstructured data",
types=[ FILE, PAGE ],
contents=[
EntityReferenceFilter(
id="{content-id}"
)
]
)
)from graphlit import Graphlit
from graphlit_api import *
response = await graphlit.client.query_contents(
filter=ContentFilter(
search_type=VECTOR,
search="Unstructured data",
types=[ FILE, PAGE ],
contents=[
EntityReferenceFilter(
id="{content-id}"
)
]
)
)
BUILT FOR DEVELOPERS, BY DEVELOPERS
BUILT FOR DEVELOPERS, BY DEVELOPERS
BUILT FOR DEVELOPERS, BY DEVELOPERS
Zero deployment
Zero deployment
Zero deployment
Managed API for easy integration
No infrastructure to be deployed
Serverless, cloud-native platform
Multitenant-ready with RBAC
Data is encrypted-at-rest
Usage-based pricing
Our platform.
Your applications.
Any unstructured data.
Our platform.
Your applications.
Any unstructured data.
For developers building chatbots, copilots,
or vertical AI applications
with domain-specific data
For developers building chatbots, copilots, or vertical AI applications
with domain-specific data
For developers building chatbots, copilots,
or vertical AI applications
with domain-specific data
Pricing
How much does Graphlit cost?
Free to get started, no credit card required.
With our paid tiers, your costs are based on how much content you ingest -
plus the usage costs of features such as audio transcription,
AI model usage or PDF OCR text extraction.
Usage-based pricing starts at $0.10/credit
Example: an hour long podcast, automatically transcribed, and made searchable and conversational via LLMs uses 8 credits ($0.80).
If one of these pricing tiers doesn't fit your needs, let's talk.
Free to get started, no credit card required.
With our paid tiers, your costs are based on how much content you ingest -
plus the usage costs of features such as audio transcription, AI model usage or PDF OCR text extraction.
Usage-based pricing starts at $0.10/credit
Example: an hour long podcast, automatically transcribed, and made searchable and conversational via LLMs uses 8 credits ($0.80).
If one of these pricing tiers doesn't fit your needs, let's talk.
Free
$0
per/month
Ingest any content type
(i.e. PDFs, MP3s, web pages)
Create content feeds
(i.e. RSS, Web, Notion, blob storage)
Search content by
text or vector similarity
Filter content by metadata
Create chatbot conversations
over your content
Configure content workflows
Includes Deepgram audio transcription
Includes all vector embeddings
and prompt completions
Supports multi-tenant apps
Includes 1GB content storage
Includes 1000 content items
Includes 3 feeds
Includes 100 chatbot
conversations
Community Discord support
Hobby
$49
/month + usage
Everything in Free tier
$0.10/credit usage
Includes 10GB content storage
Includes 10K content items
Includes 10 feeds
Unlimited chatbot conversations
Email and community Discord support
Starter
$199
/month + usage
Everything in Hobby tier
$0.09/credit usage (10% off)
Includes 100GB content storage
Includes 100K content items
Unlimited feeds
Unlimited chatbot conversations
Priority email, private Slack support
Growth
$999
/month + usage
Everything in Starter tier
$0.08/credit usage (20% off)
Unlimited content storage
Unlimited content items
Unlimited feeds
Unlimited chatbot conversations
Priority email, private Slack support
Dedicated technical contact
SLA (coming soon)
SOC 2 (coming soon)
Newsletter
Get Graphlit updates to your inbox
Contact Us
Got questions?
We would be happy to talk about what you're building.
Email questions@graphlit.com, or schedule a call below.
We would be happy to talk about what you're building.
Email questions@graphlit.com, or
join us on Discord and let's chat.
We would be happy to talk about what you're building.
Email questions@graphlit.com, or
join us on Discord and let's chat.
Can I use this to build a chatbot or copilot?

Definitely! Graphlit provides everything you need to build a RAG application, such as a chatbot or copilot, with our easy-to-use API. Compared to the OpenAI Assistants API, Graphlit handles a wider range of content formats, and offers higher limits on storage capacity. Also, we provide vector-based semantic search as well as RAG conversations. In addition to a small monthly platform fee, you are charged for credit usage based on the volume of content ingested into the platform, LLM tokens used, and other cloud API usage. But you can also bring your own LLM keys, and pay for those tokens yourself.
Can I extract text from PDFs or Word documents?
Yes! You can ingest any type of document, including PDF, Word document, Powerpoint presentation, Markdown, etc. and Graphlit will extract structured text. You can optionally use a content workflow with Azure AI Document Intelligence models, for high-quality OCR text and table extraction. In our testing, we have seen comparable or better results using Azure AI Document Intelligence for OCR, compared to Unstructured.IO, LlamaParse, and other open source PDF extractors.
How is this different than LangChain?
LangChain is a leading frameworks for building LLM applications, but it is not a managed platform. When building RAG applications, you would need to integrate LangChain with LLMs, vector databases, and cloud infrastructure. There are many pieces to assemble to have a production-grade application with LangChain, and you are left to solve these DevOps problems yourself. WIth Graphlit, you can start building your RAG application immediately - no assembly required. We provide a scalable, managed API, where you just have to point us at your unstructured data, and we do the rest. We handle text extraction, text chunking, vector embeddings, as well as RAG conversations (with history). Also, Graphlit handles multi-tenant semantic search out of the box.
How is this different than Unstructured.IO?
Unstructured.IO is focused on the extraction of text from PDFs and other documents, and the partitioning of those documents. They are not a RAG-ready platform, in that they don't directly connect your data to LLMs. They are also not multimodal-ready. They are currently focused on textual formats, not any other media formats. You still need to build an end-to-end unstructured data pipeline around their technology. By using Graphlit, you can start building multimodal RAG applications immediately - no assembly required. We offer best-in-class OCR and text extraction, using Azure AI Document Intelligence. Graphlit also supports a wider range of file formats and metadata than Unstructured.IO, and has built-in audio transcription.
Do I need my own vector database, like Pinecone or Qdrant?
Nope! With Graphlit, you get everything you need to create RAG applications out of the box. We already have integrated best-in-class vector search and vector embeddings into the platform.
Do you support a JSON mode for text extraction?
Yes! Graphlit stores extracted text and tables in our own JSON format, which you can access through our API. You have the option of using Graphlit for ingestion and text extraction only, and then post-processing the JSON format with your own application. But in most cases, you would have Graphlit generate vector embeddings from the extracted text, and handle the RAG conversations for you.
Do you support audio and video transcription?
For sure, we handle a variety of audio and video formats, such as MP4, MP3, WAV and AAC/M4A. Any audio or video file ingested into Graphlit will have audio automatically transcribed using the latest Deepgram speech-to-text model.
Can I build a knowledge graph from my data?
Certainly! Graphlit automatically builds a knowledge graph from the content you ingest into the platform. We maintain the relationships between your content, and the content sources (i.e. feeds). Optionally, you can enable entity extraction to identify people, places, organizations, products, etc. from your text or transcriptis, and add those to your knowledge graph. You can also enable entity enrichment to connect Wikipedia, Crunchbase or other APIs, and import additional metadata into the knowledge graph.
Do you offer a free trial?
Good question! When you signup to Graphlit, you are on the Free Tier. This gives you full access to all the features of the Graphlit API, with no trial expiration. You are only limited by the amount of content you can ingest into your account. By adding a payment method, you can upgrade to a paid tier, which gives higher quota limits - and you will pay a flat monthly platform fee, and any credit usage.
Can I use this to build a chatbot or copilot?
Definitely! Graphlit provides everything you need to build a RAG application, such as a chatbot or copilot, with our easy-to-use API. Compared to the OpenAI Assistants API, Graphlit handles a wider range of content formats, and offers higher limits on storage capacity. Also, we provide vector-based semantic search as well as RAG conversations. In addition to a small monthly platform fee, you are charged for credit usage based on the volume of content ingested into the platform, LLM tokens used, and other cloud API usage. But you can also bring your own LLM keys, and pay for those tokens yourself.
Can I extract text from PDFs or Word documents?
Yes! You can ingest any type of document, including PDF, Word document, Powerpoint presentation, Markdown, etc. and Graphlit will extract structured text. You can optionally use a content workflow with Azure AI Document Intelligence models, for high-quality OCR text and table extraction. In our testing, we have seen comparable or better results using Azure AI Document Intelligence for OCR, compared to Unstructured.IO, LlamaParse, and other open source PDF extractors.
How is this different than LangChain?
LangChain is a leading frameworks for building LLM applications, but it is not a managed platform. When building RAG applications, you would need to integrate LangChain with LLMs, vector databases, and cloud infrastructure. There are many pieces to assemble to have a production-grade application with LangChain, and you are left to solve these DevOps problems yourself. WIth Graphlit, you can start building your RAG application immediately - no assembly required. We provide a scalable, managed API, where you just have to point us at your unstructured data, and we do the rest. We handle text extraction, text chunking, vector embeddings, as well as RAG conversations (with history). Also, Graphlit handles multi-tenant semantic search out of the box.
How is this different than Unstructured.IO?
Unstructured.IO is focused on the extraction of text from PDFs and other documents, and the partitioning of those documents. They are not a RAG-ready platform, in that they don't directly connect your data to LLMs. They are also not multimodal-ready. They are currently focused on textual formats, not any other media formats. You still need to build an end-to-end unstructured data pipeline around their technology. By using Graphlit, you can start building multimodal RAG applications immediately - no assembly required. We offer best-in-class OCR and text extraction, using Azure AI Document Intelligence. Graphlit also supports a wider range of file formats and metadata than Unstructured.IO, and has built-in audio transcription.
Do I need my own vector database, like Pinecone or Qdrant?
Nope! With Graphlit, you get everything you need to create RAG applications out of the box. We already have integrated best-in-class vector search and vector embeddings into the platform.
Do you support a JSON mode for text extraction?
Yes! Graphlit stores extracted text and tables in our own JSON format, which you can access through our API. You have the option of using Graphlit for ingestion and text extraction only, and then post-processing the JSON format with your own application. But in most cases, you would have Graphlit generate vector embeddings from the extracted text, and handle the RAG conversations for you.
Do you support audio and video transcription?
For sure, we handle a variety of audio and video formats, such as MP4, MP3, WAV and AAC/M4A. Any audio or video file ingested into Graphlit will have audio automatically transcribed using the latest Deepgram speech-to-text model.
Can I build a knowledge graph from my data?
Certainly! Graphlit automatically builds a knowledge graph from the content you ingest into the platform. We maintain the relationships between your content, and the content sources (i.e. feeds). Optionally, you can enable entity extraction to identify people, places, organizations, products, etc. from your text or transcriptis, and add those to your knowledge graph. You can also enable entity enrichment to connect Wikipedia, Crunchbase or other APIs, and import additional metadata into the knowledge graph.
Do you offer a free trial?
Good question! When you signup to Graphlit, you are on the Free Tier. This gives you full access to all the features of the Graphlit API, with no trial expiration. You are only limited by the amount of content you can ingest into your account. By adding a payment method, you can upgrade to a paid tier, which gives higher quota limits - and you will pay a flat monthly platform fee, and any credit usage.