
With the wide variety of Large Language Models (LLMs) available today, and with the recent announcement of OpenAI Assistants, I thought it would be interesting to compare several Retrieval Augmented Generation (RAG) based chatbots and copilots.
Large Language Models
Each model has its nuances, and some things that it does better or worse than others, but it isn't always clear which model to use in which situation.
Also you have to be aware of the costs associated with each model, when selecting one for your own chatbot or copilot. While the newer GPT-4 Turbo 128K model shows better results than GPT-3.5 Turbo 16K, it is 10x more expensive for input tokens (and 15x more expensive for output tokens).
In the next blog post, we'll compare using Graphlit for building your own RAG copilots, and see how the responses compare to the copilots shown below.
Head-to-Head Comparison
Let's compare the RAG output across several LLMs and chatbot / copilot applications.
For this comparison, we will use the following models / applications:
- OpenAI Assistant, with GPT-4 Turbo 128K (1106) model
- OpenAI Assistant, with GPT-3.5 Turbo 16K (1106) model
- Anthropic Claude 2.1
- Perplexity (Copilot mode was off)
- OpenGPTs, with GPT-3.5 Turbo
- Chatbase, with GPT-3.5 Turbo
We will use this podcast episode, from the MapScaping podcast that was discussed in the previous blog post.
I've started by uploading the timestamped text transcript from this 42-minute podcast episode to each application. (The podcast episode was transcribed with the Deepgram Nova 2 model.)
Example:
[00:00:02] That day's data or that week's data, but once it starts to age out a little bit, it goes dark. And and that kinda sort of dark data concept is something that that is starting to be an industry term.
[00:00:13] Welcome to another episode of the Mapscaping podcast. My name is Daniel, and this is a podcast for the geospatial community. My guest on the show today is Kirk Marple. Kirk is the founder of Unstruct Data. And today on the podcast, we're talking about unstructured data, but we cover a few other sort of interesting concepts along the way. So Kirk is gonna introduce us to the idea of 1st, 2nd, and 3rd order metadata
[00:00:37] will touch briefly on edge computing and knowledge graphs. Just before we get started, I wanna say a big thank you to Lizzie, who who is one of the brand new supporters of this podcast on Patreon, and, of course, to all the other people that are supporting this podcast via Patreon. If that's something you might be interested in, you'll find a link to the Mapscaping Patreon account in the show notes of this podcast episode.
Using the OpenAI Tokenizer, this transcript contains:

Walkthrough
To test each RAG-based chatbot, I asked the same four questions about the podcast transcript:
- Kirk mentioned first, second, and third-degree meta data, what did he mean by that?
- What was Kirk's advice to people building geospatial software today?
- What is unstructured data?
- Summarize this episode in 500 words or less
Copilots
Below I'm showing screenshots of the responses from each copilot, for each of the four questions above.
You'll notice that some of the copilots like OpenAI Assistant supported inline citations, while others did not.
We are just covering the freely available copilot applications here, and not covering OSS models like Llama 2 or Mistral. I plan to review and compare those in a future blog post.
For each, I've added my notes on the responses, which are just my personal opinions.
OpenAI Assistant (GPT-4 Turbo 128K 1106)
NOTES:
- Interestingly, for the first question, it doesn't answer correctly about "Second-order metadata", but if you look at the fourth question, it described it properly in the summary.
- For the second question, it does a nice job of mentioning the use of an "ensemble of models" to identify real-world context.
- For the third question, the description of unstructured data was a bit sparse.
- It does arguably the best job on the episode summary, especially calling out the "misnomer" of the term unstructured data, and references the ties between unstructured and geospatial data.




OpenAI Assistant (GPT-3.5 Turbo 16K 1106)
NOTES:
- For the first question, GPT-3.5 Turbo 16K model actually does a better job than GPT-4 Turbo 128K when answering about "Second-order metadata".
- The answers to the second and third questions are correct, albeit somewhat terse.
- The summary from the fourth question seems OK, but limited in comparison to the GPT-4 version. If posting this on an episode page for the podcast, the GPT-4 version would be much more preferred.




Anthropic Claude 2.1
NOTES:
- On the second question, Claude noted that it couldn't answer the question specifically, but followed up with more broad commentary pulled from the transcript.
- Claude appears to lean towards 'summarization' in its responses, possibly from its default system prompt. Even though I didn't specifically ask for a summary, it tended to respond with "in summary…" at the end of its response.
- Claude likes to respond with lists, even if you don't ask explicitly for them.
- Claude likes to preface its responses with a reflection of what you asked, such as where it starts with "Here is a 447-word summary…"
- For the fourth question, the Claude summary is one of the best across all the models. If you removed the prefix sentence, it would be ready to paste into an episode's show notes.



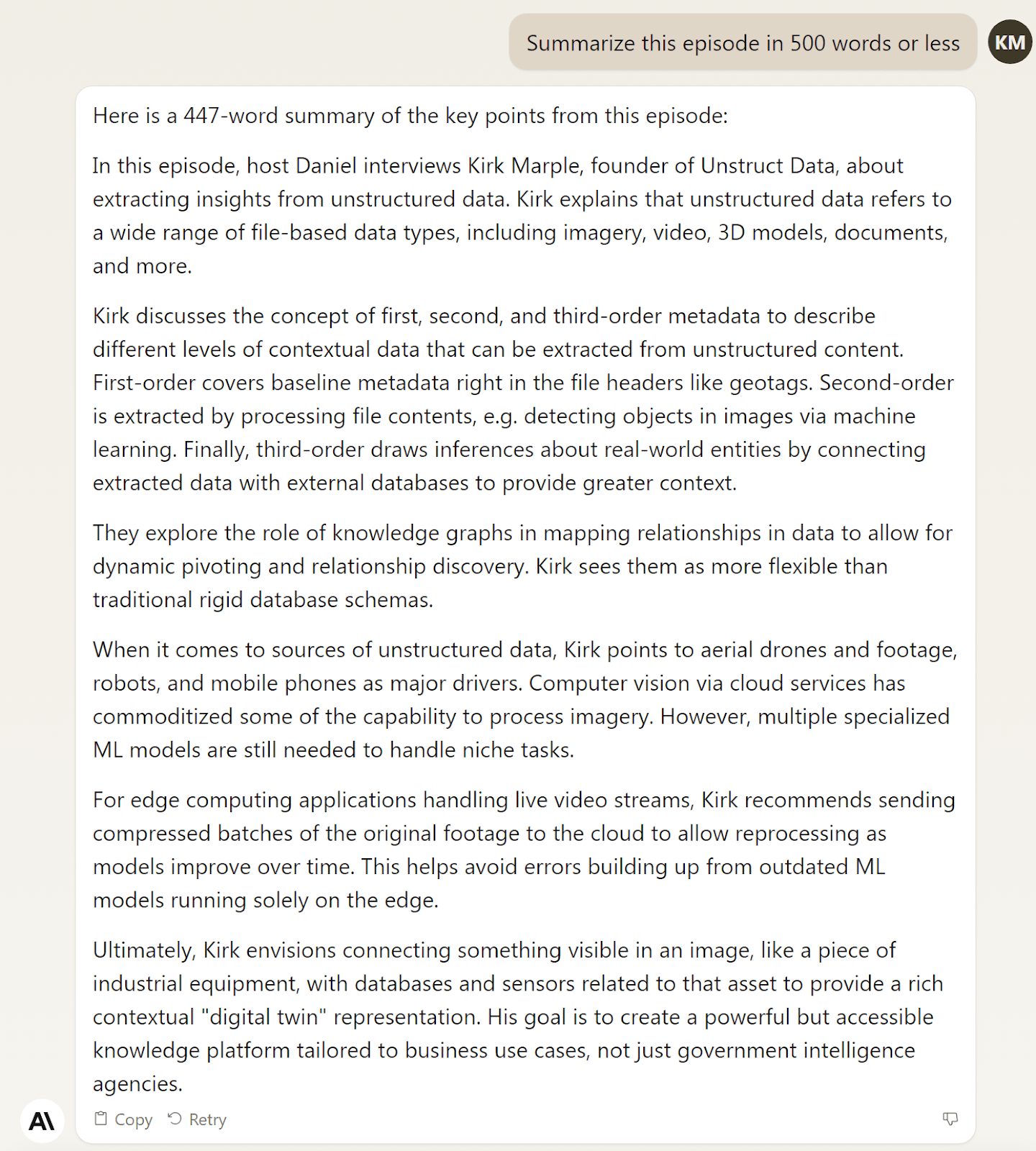
Perplexity
NOTES:
- Perplexity was unable to answer the second and fourth questions, given the uploaded transcript.
- The answers to the first and third questions are acceptable. They don't break out the topics into bullet points or lists, but as a single paragraph, they'd work in the right situation.

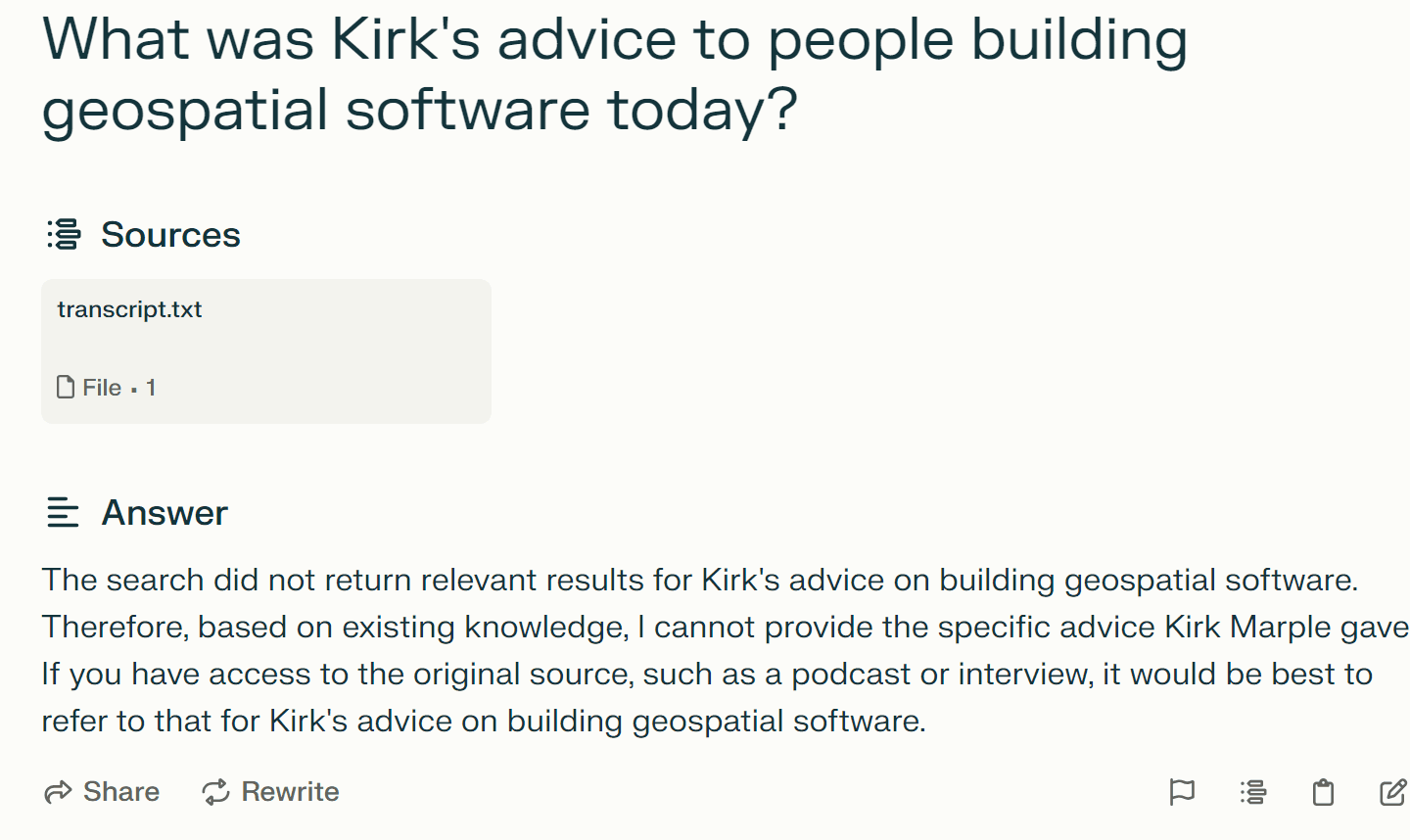

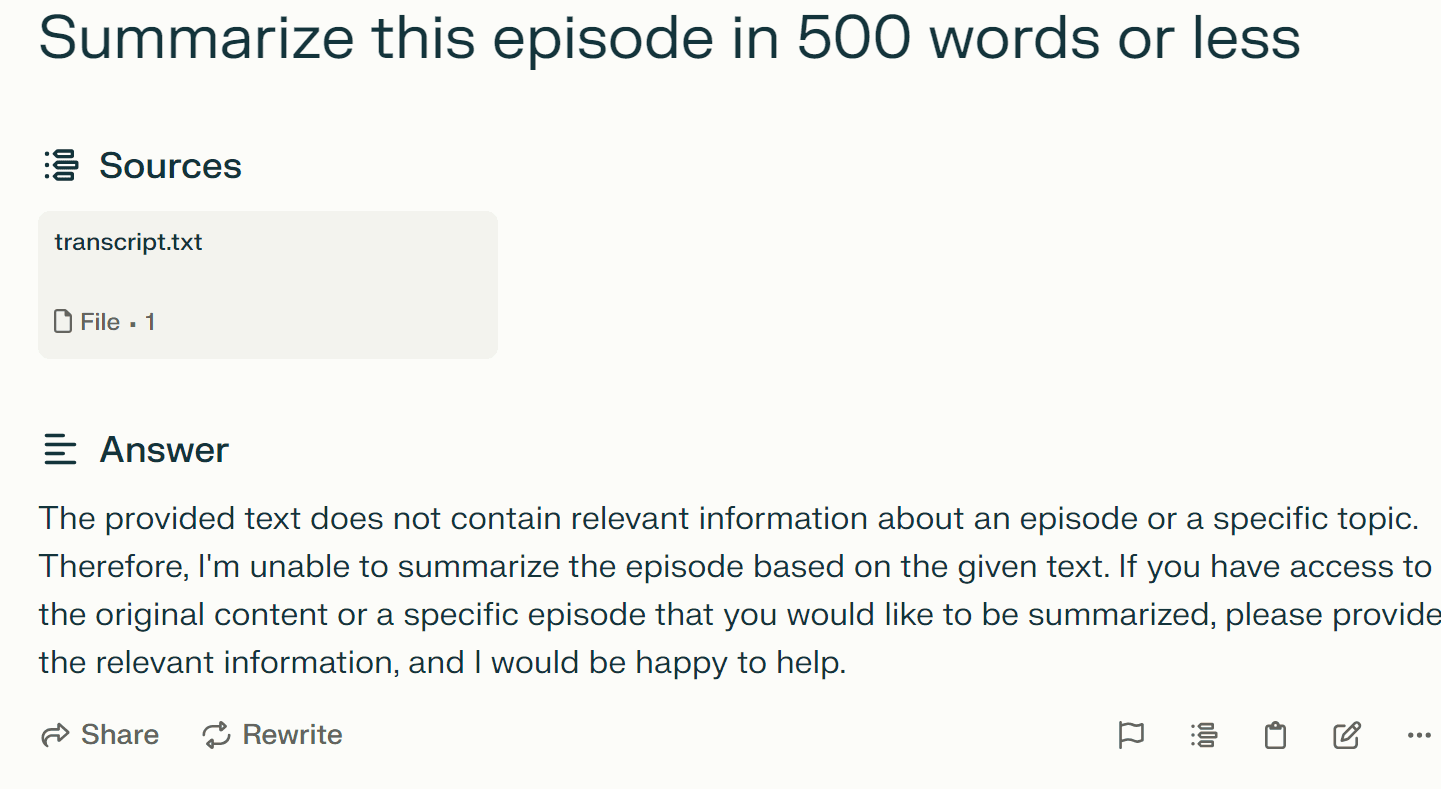
OpenGPTs (GPT-3.5 Turbo)
NOTES:
- By default, it appears OpenGPTs is using query rewriting to rewrite the user prompt before sending to the LLM for completion.
- OpenGPTs (with GPT-3.5 Turbo) was unable to answer the third question.
- The responses look similar to OpenAI Assistants, from their formatting, and give respectable results. The summary from the fourth question is especially nice.


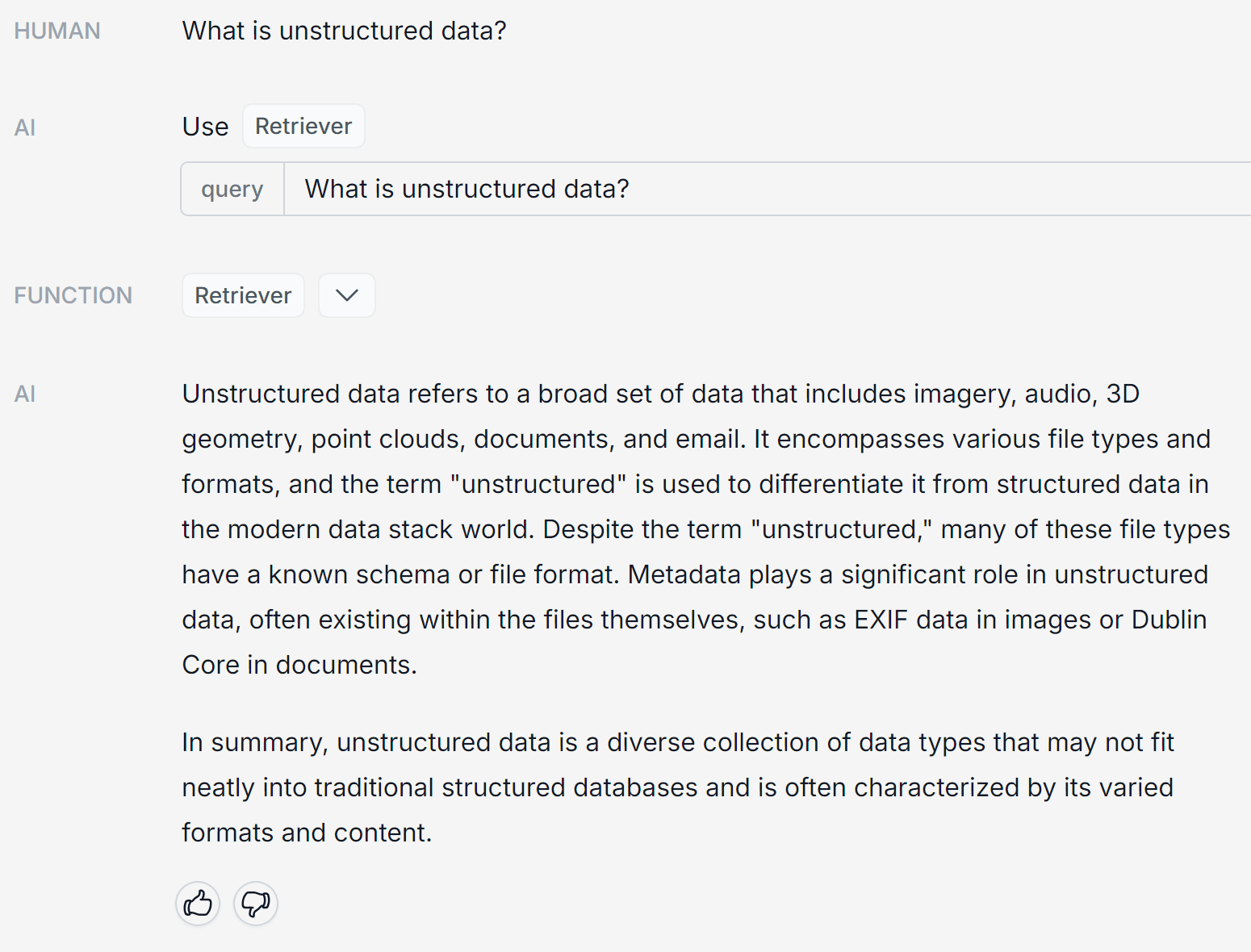
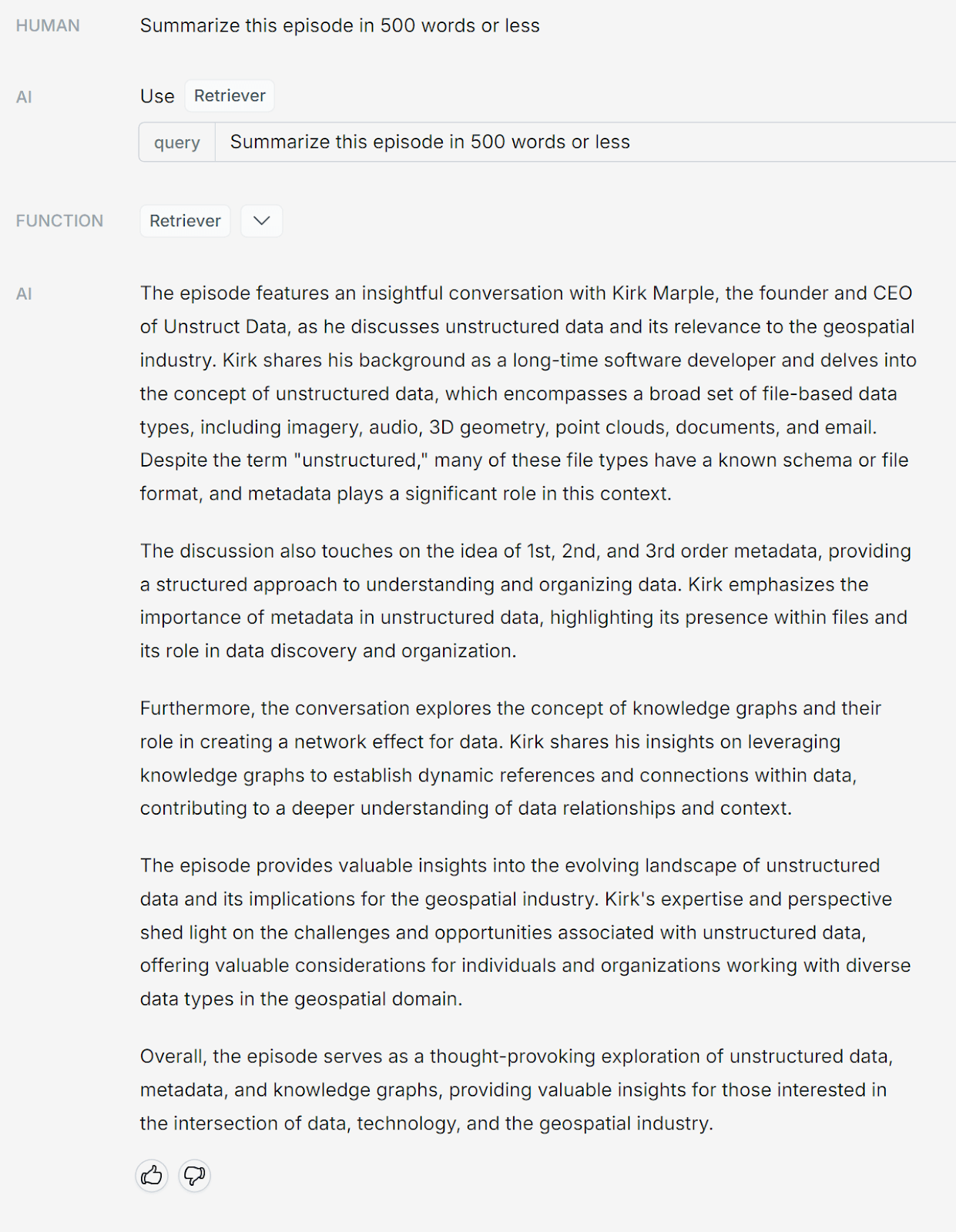
Chatbase (GPT-3.5 Turbo)
NOTES:
- Across the board, Chatbase did a nice job with each question. It didn't break out topics into bullet points or lists, but gave comprehensive results in paragraph format.
- Interestingly, Chatbase wrote the summary from the fourth question in first-person (I had the pleasure…), while all the other copilots responded in third-person.






Summary
All in all, OpenAI Assistant (GPT-4 Turbo 1106) and Claude 2.1 fared best, especially when summarizing the episode transcript. Not surprisingly, since they are the largest LLMs tested, as well as being the most pricey.
For the first question, all the copilots did rather well, and pulled out the main points. (Except, surprisingly on OpenAI GPT-4 which I mentioned above.)
We did see several questions which the RAG copilots were unable to answer from the sources. This may be do to their content retrieval algorithm and how they chunk the text from the transcript.
Also, it appeared that some of the copilots had system prompts assigned which influenced their writing style and overall "chatty" feel.
With every new generation of LLM, the bar gets higher, and we should see more consistent results to simple questions like these over document text and audio transcripts.
But there is still configuration and tuning needed to get the best results out of any RAG solution.
Next Time
In our next tutorial, I'll show how to use Graphlit to build a RAG copilot (via GraphQL API calls), and compare the results to the copilots shown here.
Please email any questions on this article or the Graphlit Platform to questions@graphlit.com.
For more information, you can read our Graphlit Documentation, visit our marketing site, or join our Discord community.