
Text-to-speech models such as those from ElevenLabs have become incredibly human-sounding, and have the ability to clone your own voice.
Now, the Graphlit Platform can be used to generate audio with ElevenLabs voices from any content - web pages, PDFs, audio transcripts and more.
Say we want to generate a podcast about this week's interesting AI news and academic papers.
🔉 Listen to an example here.
We first need to ingest some content to use for our podcast. We'll start by ingesting an interesting blog post about knowledge graphs, but we also want to crawl any hyperlinks and ingest the ArXiV papers referenced in the blog post.
After ingesting all the content we want to use for the podcast, we'll create an LLM specification for the latest GPT-4 Turbo (0125) model, and then will publish summarized versions of our content as an MP3 audio file using an ElevenLabs voice.
Once the publishing has completed, you can download the MP3 to post on social media or upload to a media hosting site.
You can use any content you want with this audio publishing process, create your own LLM publishing prompt, and select any ElevenLabs voice.
Create Workflow
To crawl the links automatically, we need to create a workflow object which enables crawling of Web page hyperlinks.
Mutation:
mutation CreateWorkflow($workflow: WorkflowInput!) {
createWorkflow(workflow: $workflow) {
id
name
state
}
}
Variables:
{
"workflow": {
"enrichment": {
"link": {
"enableCrawling": true,
"allowedLinks": [
"WEB"
],
"maximumLinks": 10
}
},
"name": "AI Podcast Workflow"
}
}
Response:
{
"id": "1ee5b5dd-f445-4aff-b492-f4178e7e8550",
"name": "AI Podcast Workflow",
"state": "ENABLED"
}
Ingest Contents
To ingest a web page, we will specify the uri and the workflow id we created above, since we want to crawl any hyperlinks we find in this blog post.
You can repeat this process for any other content you want to include in your AI-generated podcast, and you aren't limited just to web pages. You can use audio transcripts, PDFs, Word documents, or even Slack or email.
Mutation:
mutation IngestPage($name: String, $uri: URL!, $id: ID, $workflow: EntityReferenceInput) {
ingestPage(name: $name, uri: $uri, id: $id, workflow: $workflow) {
id
name
state
type
uri
}
}
Variables:
{
"uri": "https://towardsdatascience.com/ultra-foundation-models-for-knowledge-graph-reasoning-9f8f4a0d7f09#71ab",
"workflow": {
"id": "1ee5b5dd-f445-4aff-b492-f4178e7e8550"
}
}
Response:
{
"type": "PAGE",
"uri": "https://towardsdatascience.com/ultra-foundation-models-for-knowledge-graph-reasoning-9f8f4a0d7f09#71ab",
"id": "0c350de4-0e5d-40c8-8245-8b32e44cbd77",
"name": "ULTRA: Foundation Models for Knowledge Graph Reasoning | by Michael Galkin | Towards Data Science",
"state": "CREATED"
}
Create Specification
Once we have the content we want to publish, let's use the GPT-4 Turbo (0125) model to publish the script which will be provided to the ElevenLabs text-to-speech API.
Here we specify the OPEN_AI service, and the GPT4_TURBO_128K_0125 model.
Creating a specification is optional, but GPT-4 tends to give better quality output for the publishing process.
Mutation:
mutation CreateSpecification($specification: SpecificationInput!) {
createSpecification(specification: $specification) {
id
name
state
type
serviceType
}
}
Variables:
{
"specification": {
"type": "COMPLETION",
"serviceType": "OPEN_AI",
"openAI": {
"model": "GPT4_TURBO_128K_0125"
},
"name": "GPT-4 0125"
}
}
Response:
{
"type": "COMPLETION",
"serviceType": "OPEN_AI",
"id": "12748d8b-16f8-4c94-a71c-ccd1ced57322",
"name": "GPT-4 0125",
"state": "ENABLED"
}
Publish Contents
We're now ready to publish our AI-generated podcast. Listen to an example here.
We first need to tell Graphlit that we want to use ELEVEN_LABS_AUDIO as our publishing type, with the MP3 format. We are using the ENGLISH_V1 model with a British male voice. You can find all the supported the voice IDs on the ElevenLabs website.
We are also assigning the publishSpecification to the GPT-4 specification we created above.
Here is the publish prompt used for this podcast:
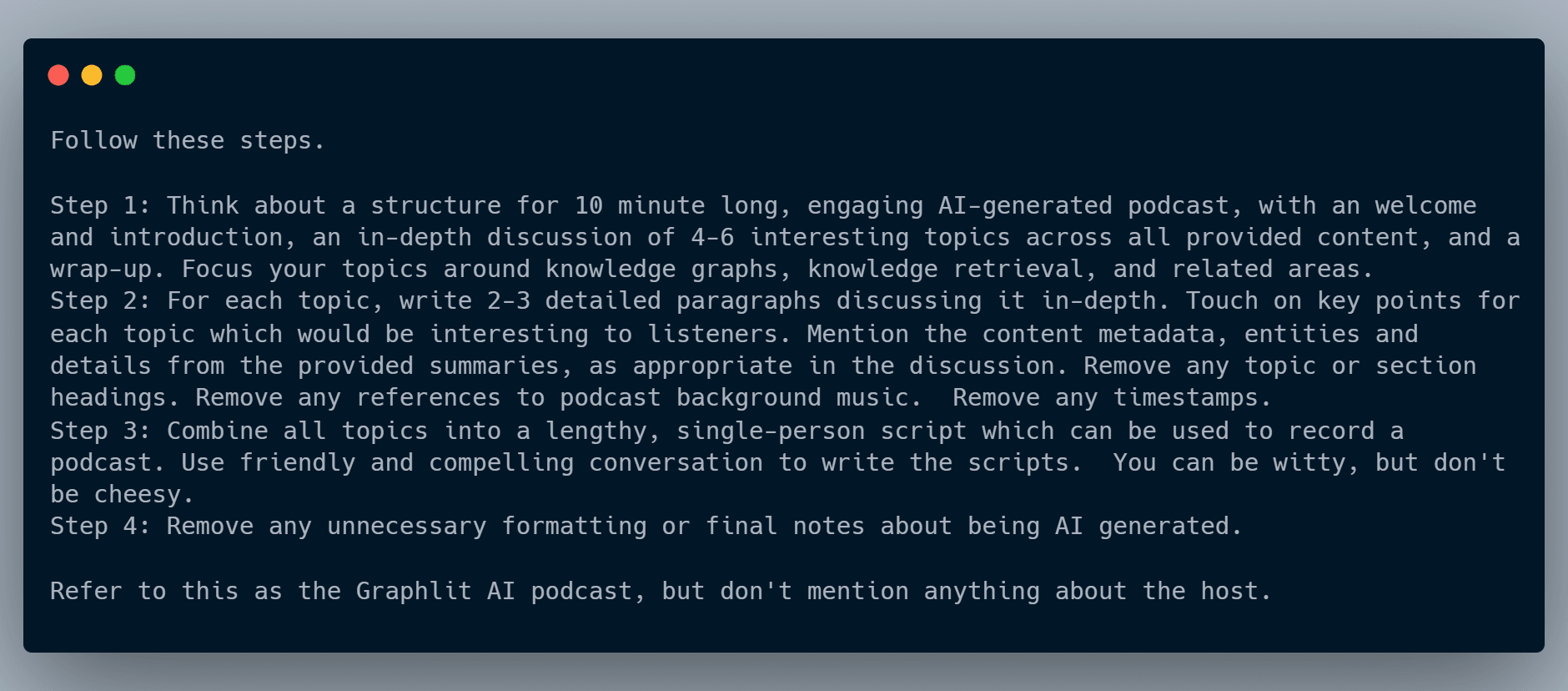
Graphlit will summarize each of the contents that we ingested, and then use the publishing prompt provided to generate the final script which is passed to the ElevenLabs text-to-speech API.
This process takes a few minutes to complete, and when the publishContents mutation finishes, your MP3 will be ready for download.
Mutation:
mutation PublishContents($summaryPrompt: String, $publishPrompt: String!, $connector: ContentPublishingConnectorInput!, $filter: ContentFilter, $name: String, $summarySpecification: EntityReferenceInput, $publishSpecification: EntityReferenceInput, $workflow: EntityReferenceInput) {
publishContents(summaryPrompt: $summaryPrompt, publishPrompt: $publishPrompt, connector: $connector, filter: $filter, name: $name, summarySpecification: $summarySpecification, publishSpecification: $publishSpecification, workflow: $workflow) {
id
name
creationDate
state
uri
type
fileType
mimeType
fileName
fileSize
}
}
Variables:
{
"publishPrompt": "Follow these steps.\\n\\nStep 1: Think about a structure for 10 minute long, engaging AI-generated podcast, with an welcome and introduction, an in-depth discussion of 4-6 interesting topics across all provided content, and a wrap-up. Focus your topics around knowledge graphs, knowledge retrieval, and related areas.\\nStep 2: For each topic, write 2-3 detailed paragraphs discussing it in-depth. Touch on key points for each topic which would be interesting to listeners. Mention the content metadata, entities and details from the provided summaries, as appropriate in the discussion. Remove any topic or section headings. Remove any references to podcast background music. Remove any timestamps.\\nStep 3: Combine all topics into a lengthy, single-person script which can be used to record a podcast. Use friendly and compelling conversation to write the scripts. You can be witty, but don't be cheesy.\\nStep 4: Remove any unnecessary formatting or final notes about being AI generated. \\n\\nRefer to this as the Graphlit AI podcast, but don't mention anything about the host.",
"connector": {
"type": "ELEVEN_LABS_AUDIO",
"format": "MP3",
"elevenLabs": {
"model": "ENGLISH_V1",
"voice": "NO8iseyk20Aw8Lx2NvBu"
}
},
"publishSpecification": {
"id": "12748d8b-16f8-4c94-a71c-ccd1ced57322"
}
}
Response:
{
"type": "FILE",
"mimeType": "audio/mp3",
"fileType": "AUDIO",
"fileSize": 4145319,
"uri": "https://redacted.blob.core.windows.net/files/ccd78bbd-7f26-4964-99e9-e231459b4c08/Content.mp3",
"id": "ccd78bbd-7f26-4964-99e9-e231459b4c08",
"name": "Content.mp3",
"state": "CREATED",
"creationDate": "2024-02-03T03:50:15Z"
}
Get Published MP3
Once you've published your audio file, you can easily get a URI to download it.
Query the content via the id returned from publishContents, and the masterUri provides a temporary URI for download. Since the published content is re-ingested into Graphlit, you can look at transcriptUri for the audio transcript automatically generated from the MP3.
Query:
query GetContent($id: ID!) {
content(id: $id) {
id
name
creationDate
state
originalDate
finishedDate
workflowDuration
uri
type
fileType
mimeType
fileName
fileSize
masterUri
mezzanineUri
transcriptUri
}
}
Variables:
{
"id": "ccd78bbd-7f26-4964-99e9-e231459b4c08"
}
Response:
{
"type": "FILE",
"mimeType": "audio/mp3",
"fileType": "AUDIO",
"fileName": "Content.mp3",
"fileSize": 4145319,
"masterUri": "https://redacted.blob.core.windows.net/files/ccd78bbd-7f26-4964-99e9-e231459b4c08/Content.mp3?sv=2023-11-03&se=2024-02-03T09%3A50%3A15Z&sr=c&sp=rl&sig=v3VHjZz3NGVbHqksmVtmZJiMssC7RMaZJ6DWemkx2MA%3D",
"mezzanineUri": "https://redacted.blob.core.windows.net/files/ccd78bbd-7f26-4964-99e9-e231459b4c08/Mezzanine/Content.mp3?sv=2023-11-03&se=2024-02-03T09%3A50%3A15Z&sr=c&sp=rl&sig=v3VHjZz3NGVbHqksmVtmZJiMssC7RMaZJ6DWemkx2MA%3D",
"transcriptUri": "https://redacted.blob.core.windows.net/files/ccd78bbd-7f26-4964-99e9-e231459b4c08/Transcript/Content.json?sv=2023-11-03&se=2024-02-03T09%3A50%3A15Z&sr=c&sp=rl&sig=v3VHjZz3NGVbHqksmVtmZJiMssC7RMaZJ6DWemkx2MA%3D",
"uri": "https://redacted.blob.core.windows.net/files/ccd78bbd-7f26-4964-99e9-e231459b4c08/Content.mp3",
"id": "ccd78bbd-7f26-4964-99e9-e231459b4c08",
"name": "Content.mp3",
"state": "FINISHED",
"creationDate": "2024-02-03T03:50:15Z",
"finishedDate": "2024-02-03T03:50:21Z",
"workflowDuration": "PT5.8222653S",
}
By combining the power of LLMs, such as OpenAI GPT-4 Turbo, with the latest text-to-speech models from ElevenLabs, Graphlit helps you automate the creation of AI-generated podcasts, daily audio summaries, or any other audio renditions of your ingested contents.
Summary
Please email any questions on this tutorial or the Graphlit Platform to questions@graphlit.com.
For more information, you can read our Graphlit Documentation, visit our marketing site, or join our Discord community.